
NVIDIA GeForce RTX 5080 FE 超詳實測!NVIDIA GeForce RTX 50 系列再有新成員登場,續上週開賣最強的 GeForce RTX 5090 D 後,下一級的 GeForce RTX 5080 也正式解禁。ezone.hk 今次除了解構 GeForce RTX 5080 的特點外,更找來上代 Ada Lovelace 架構同級的 GeForce RTX 4080 FE 作效能實測比較。
刻按此,用 App 睇更多產品開箱影片
NVIDIA GeForce RTX 5080 FE 實測
NVIDIA GeForce RTX 5080 作為 NVIDIA 第二款 Blackwell 顯示核心架構及 TSMC 4N 定制工藝的產品,官方定價 8,299 人民幣 (約 HK$8,923),較上代 RTX 4080 首發時的 9,499 人民幣 (約 HK$10,214) 平上 1,200 人民幣 (約 HK$1,290),跟上級 RTX 5090 D 相比,則平上 8,200 人民幣 (約 HK$8,817),今次 ezone.hk 詳細剖析 RTX 5080 FE 之特點。
Techno 01:10,752 個 CUDA Cores
GeForce RTX 5080 使用 GB203 核心,屬上線 RTX 5090 D 使用 GB202 核心的簡化版,同樣 Blackwell 顯示核心架構及 TSMC 4N 定制工藝,但內建電晶體由 922 億降至 456 億電晶體,而 Die 面積則為 378mm2,與上代 RTX 4080 使用 AD103 核心的 459 億顆電晶體及 378.6mm2 Die 面積相近。

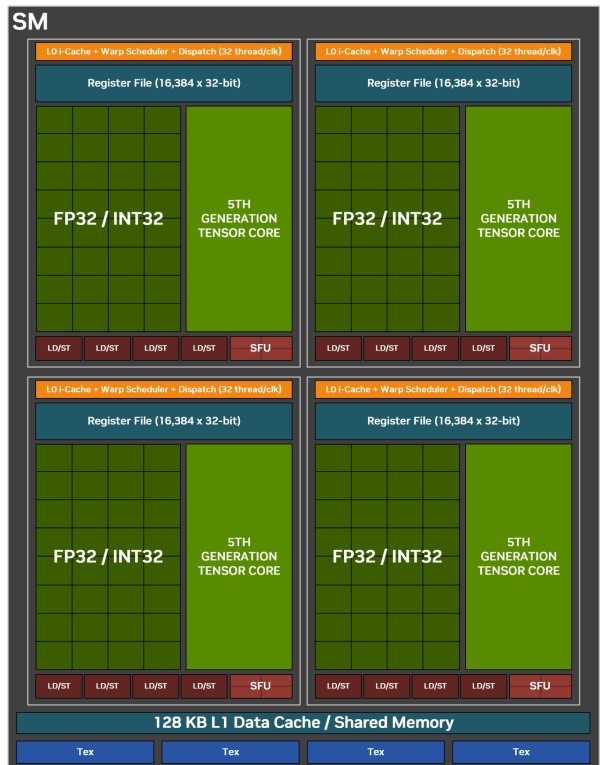
GB203 核心內建 7 個 GPC (Graphics Processing Clusters),每個 GPC 設有 8 個 TPC (Texture Processing Clusters) 及 16 個 SM(Streaming Multiprocessors) 及 16 個 ROPs ,而每個 SM 則擁有 4 組處理模組,每模組設 32 個 FP32/INT32 CUDA Cores 及 1 個 Tensor Cores。
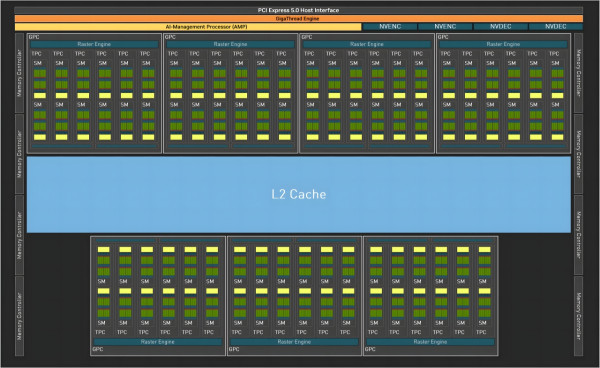
因此,GeForce RTX 5080 提供高達 10,752 個 CUDA Cores、336 個 Tensor Cores 及 84 個 RT Cores。
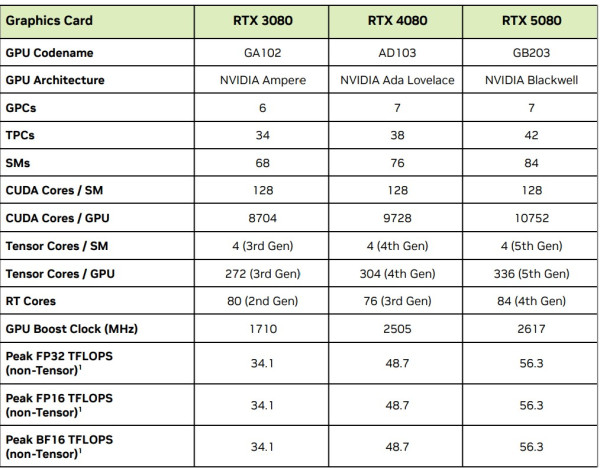
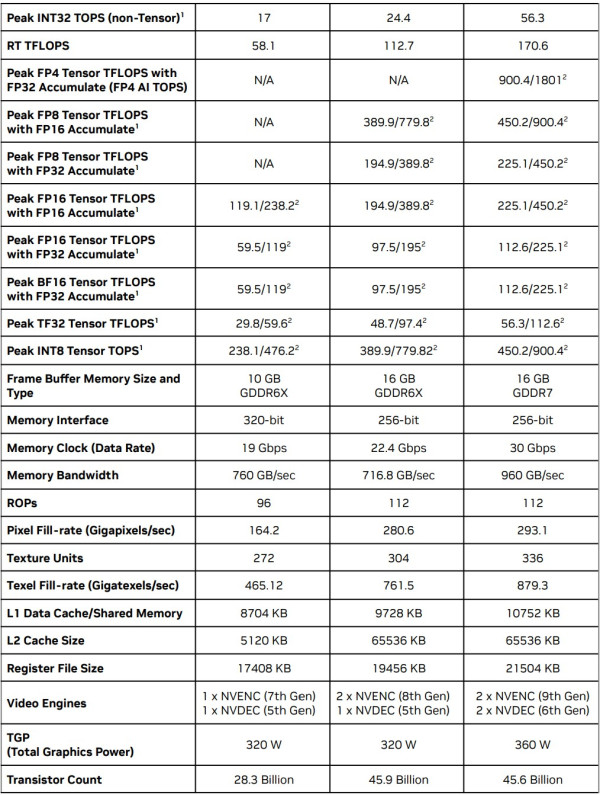
從下表下見,GeForce RTX 5080 在 CUDA Cores、Tensor Cores 及 RT Cores 數目上領先 RTX 4080,同時受惠於升級的核心架構,包括第 4 代 Tensor Cores、第 5 代 RT Cores 等,使各效能參數明顯提升。

Techno 02:256-bit GDDR7 記憶體
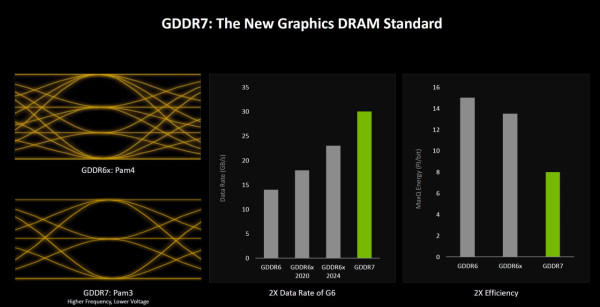
NVIDIA 在 GeForce RTX 50 系列內引入 GDDR7 記憶體支援,而 RTX 5080 是續 RTX 5090 D 後第二款使用 GDDR7 記憶體的產品。不過,為了與上線 RTX 5090 D 作出分野,GeForce RTX 5080 雖然同樣使用 GDDR7 記憶體,但核心的只內建 8 組 32-bit 記憶體控制器組成 256-bit 架構 (RTX 5090 D 則為 16 組 32-bit 共 512-bit 架構),提供 16GB 總容量。同時,NVIDIA 將 RTX 5080 的記憶體運作時脈由 RTX 5090 D 的 28Gbps 提升至 30Gbps,故仍可提供 960GB/s 的高寬頻,較上代 RTX 4080 (256-bit GDDR6X 時脈 22.4Gbps) 的 716.8GB/s 提升 34%。
Techno 03:DLSS 4 技術加持
NVIDIA 與 Blackwell 架構同時推出了 DLSS 4(Deep Learning Super Sampling 4),作為新一代的 AI 驅動升級技術,提升圖形處理的性能和畫質。
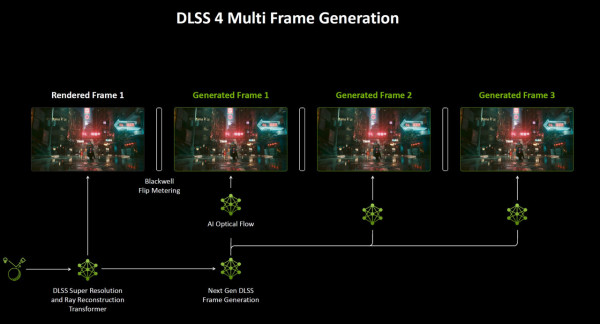
DLSS 4 的技術突破在於其多幀生成能力,這是一項基於 Transformer 模型的新技術,能顯著提高遊戲幀率並增強畫面表現力。
- 多幀生成(Multi-Frame Generation):DLSS 4 可通過生成多達 3 幀的 AI 驅動像素,實現遊戲幀數的多倍提升,達到全新的性能高度。


- 光線重建(Ray Reconstruction):優化了光追效果的細節,使畫面表現更為真實。

- 深度學習反鋸齒(DLAA):進一步提升畫面的邊緣平滑度與紋理細節,為高端顯示設備提供了絕佳的畫質支持。
DLSS 4 對各代 RTX 顯示核心支援
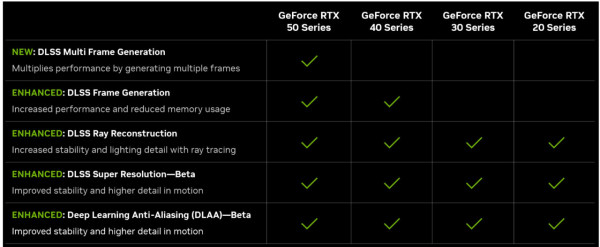
DLSS 4 是 NVIDIA 最新的 AI 驅動圖形升級技術,其支援範圍涵蓋多個世代的 RTX 顯示核心,但功能啟用程度因硬體規格而異。
RTX 50 系列:作為 Blackwell 架構的代表作,RTX 50 系列能充分發揮 DLSS 4 的全部功能,包括多幀生成(Multi-Frame Generation)、光線重建(Ray Reconstruction)及深度學習反鋸齒(DLAA),在 4K 分辨率下實現高達 8 倍的性能提升。
RTX 40 系列:DLSS 4 在 RTX 40 系列顯卡上部分功能可用,例如光線重建和 DLAA,但由於硬體限制,未能支援多幀生成,只提供基本的單幀生成。
RTX 30 系列與 RTX 20 系列:這些世代支援 DLSS 4 的基本功能如超級分辨率、光線重建及 DLAA,但無法運行進階的多幀生成技術。
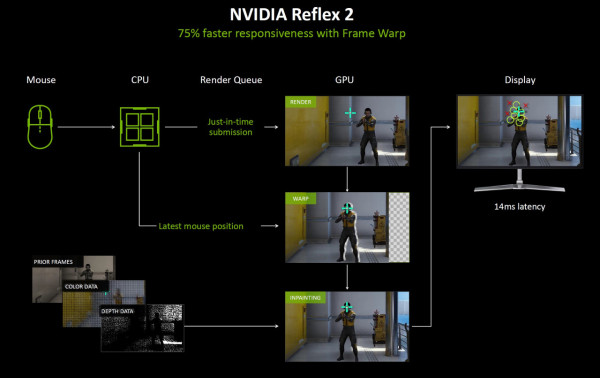
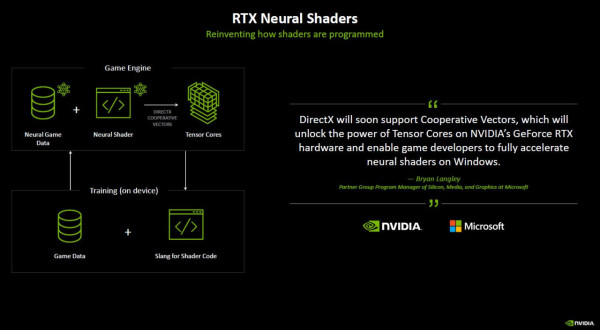
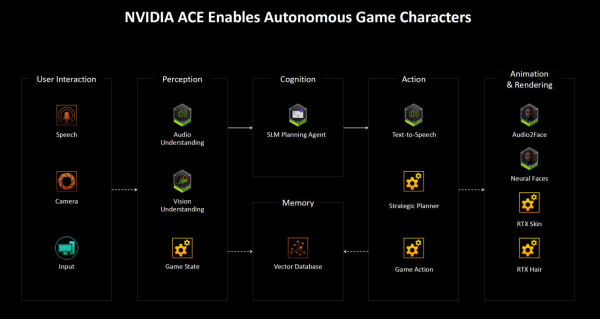
其他技術:Reflex 2 、RTX 神經渲染(Neural Rendering)、 NVIDIA ACE 等
可參考此文章:NVIDIA RTX 50 系列顯示核心完整解構!Blackwell 架構技術新時代!
解構 NVIDIA GeForce RTX 5080 FE

今次送測的 NVIDIA GeForce RTX 5080 FE (Founders Edition) 擁有高達 10,752 CUDA Cores,Boost Clock 達到 2,617MHz,配上 16GB 256-bit GDDR7 記憶體,定價為 8,299 人民幣 (約 HK$8,923) 。GeForce RTX 5080 FE 採用了全新的環保包裝理念,完全摒棄了塑料材質,體積僅為 RTX 4080 FE 包裝的一半,外觀相當低調。外包裝採用類似蘋果 iPhone 包裝封條的密封設計。

NVIDIA GeForce RTX 5080 FE (Founders Edition) 外型與上線 GeForce RTX 5090 FE 相近,全卡面為 304mm x 137mm x 40mm,只佔用 2-Slot,厚度較上 RTX 4080 FE 的 3-Slot,更適合安裝於迷你電腦機箱中。

GeForce RTX 5080 FE 能達成 2-Slot 厚度的秘密,在於採用了全新的 「雙穿透氣流」 散熱設計,包含均溫板、熱導管、散熱鰭片與雙風扇,讓顯示卡在 304 x 137 mm 的尺寸與 2-Slot 厚度 下,仍能為 RTX 4080 最高 TGP 360W 提供高效散熱。

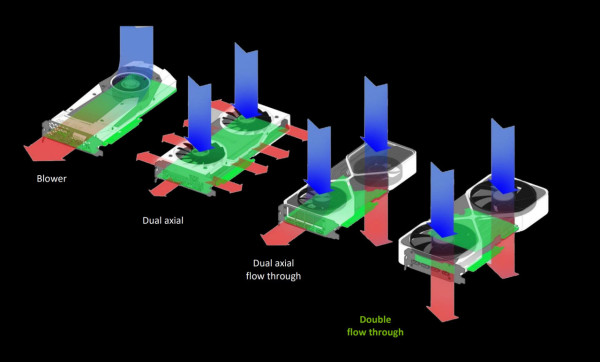

正面配備兩顆 11.5cm 軸向式風扇,透過 縮短中央電路板,讓風流得以貫穿顯示卡,提高散熱效率


GeForce RTX 5080 FE 側面設計了一個 90° 斜角的 PCIe 12V-2×6 供電接頭,這樣的設計主要用於 節省電路板空間,同時讓玩家在 使用原生線材時更容易理線,減少雜亂的佈線影響整體美觀度。


GeForce RTX 5080 FE 提供 3 個 DisplayPort 2.1b UHBR20 與 1 個 HDMI 2.1b,支援以下解析度與刷新率:
- 4K 480Hz 或 8K 165Hz DSC(DisplayPort)
- 4K 480Hz 或 8K 120Hz DSC + Gaming VRR、HDR(HDMI)
最多 4 個螢幕輸出時:最高解析度為 4K 165Hz(DP 或 HDMI);2 個螢幕輸出時最高解析度提升至 4K 360Hz 或 8K 100Hz DSC(DP 或 HDMI)。

GeForce RTX 5080 FE 配新版 「PCIe 12V-2×6 柔軟編織 PCIe 8pin 轉接線」,此新款轉接線具有 更高的柔軟度,並在接頭處增設了 額外保護層,確保玩家在裝機時不會影響接頭密合度,而 RTX 5080 需要 3 條 PCIe 8pin 轉接至 PCIe 12V-2×6。

供電方面,GeForce RTX 5080 FE 的 TGP 功耗由 RTX 4080 的 320W 升至 360W (上線 RTX 5090 D 為 585W),並要供電源供應器最低 850W 輸出。
GeForce RTX 5080 FE VS RTX 4080 FE
3D 效能、DLSS4 加速、AI 運算詳測

為了發揮 GeForce RTX 5080 FE 的最高效能,使用 24 核心、支援 PCIe 5.0 的 Intel Core i9 14900K 處理器及 ASUS ROG MAXIMUS Z790 FORMULA 主機板進行測試。
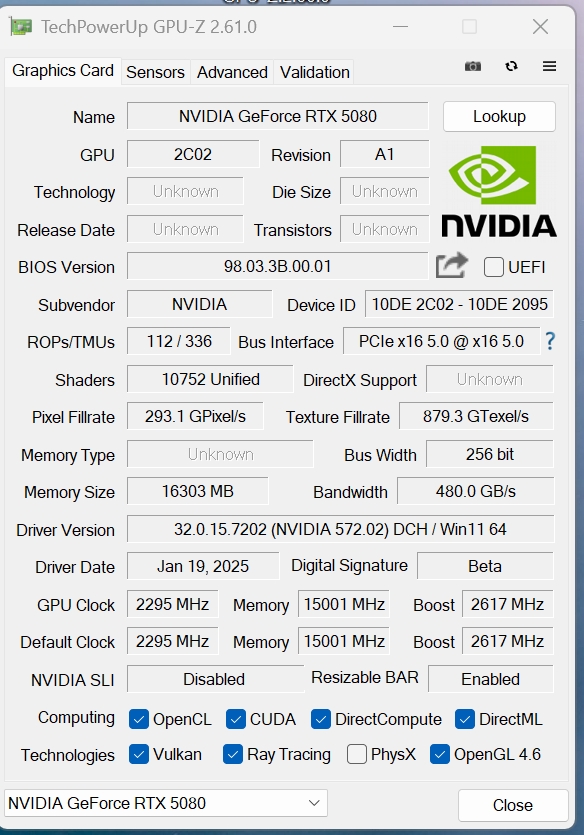
<測試平台>
●處理器:Intel Core i9 14900K● 主機板:ASUS ROG MAXIMUS Z790 FORMULA●記憶體:G.Skill Trident Z5 RGB DDR5-6000MHz 2 x 16GB●顯示卡:NVIDIA GeForce RTX 5080 FE、NVIDIA GeForce RTX 4080 FE ●SSD:WD Black SN850 NVMe SSD 2TB●作業系統:《Windows 11 Pro 24H2 64-bit》●驅動程式:NVIDIA《GeForce Driver 572.02》●散熱:ASUS ROG Strix LC II 360 ARGB
Test 01:3DMark 理論遊戲效能
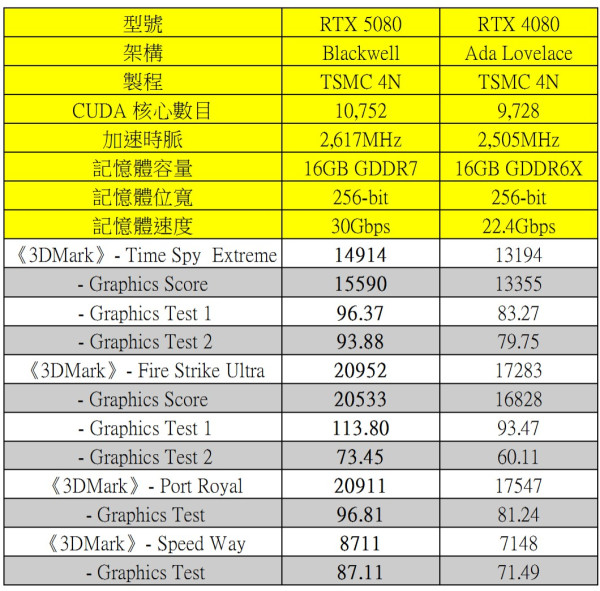
分析:新架構效能提升約 20%
NVIDIA GeForce RTX 5080 採用全新一代 Blackwell 架構的 GB203 核心,但 CUDA 數目及電晶體數目未有像上線 RTX 5090 D 般較上代大幅提升 (編按:RTX 5090 D CUDA 數目為 21,760 個、922 億顆電晶體 / RTX 4090 為 16,384 CUDA 及 763 億顆電晶體)。因此,GeForce RTX 5080 的效能提升主要來自核心架構的改進,即第 5 代 Tensor Cores 及第 4 代 RT Cores。在 《3DMark》- Fire Strike Ultra 測試中,RTX 5080 獲得 20,592 分的成績,比 RTX 4080 的 17,283 分高出約 20%,而其他《3DMark》測試項目也表現出全面提升,足證新一代 Blackwell 架構帶來的效能優勢。

Test 02:4K DLSS 4 遊戲效能
GeForce RTX 50 系列另一大賣點是完整支援 DLSS 4 (Deep Learning Super Sampling 4) 技術,當中重點的 DLSS MULTI FRAME GENRATION 功能是由 Blackwell GPU 內第 5 代 Tensor Cores 進行處理。ezone.hk 找來多款對應 DLSS 4 技術的 3D 遊戲及《3DMark》進行測試。

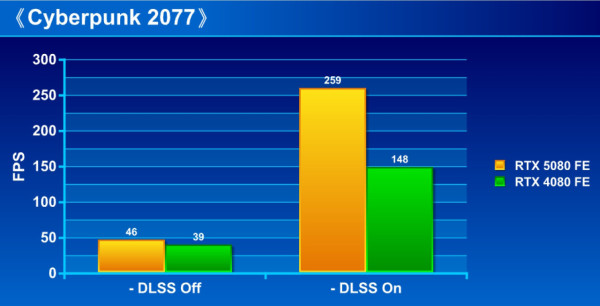
《Cyberpunk 2077》

《Cyberpunk 2077》最新更新已支援新一代 DLSS4 技術,配合 RTX 50 系列即可「DLSS Multi Frame Generation」功能,可選 2x、3x、4x 。
效能測試:
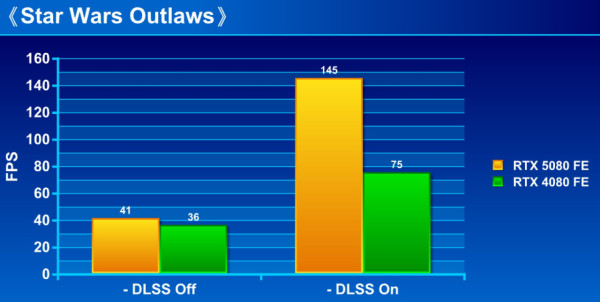
《Star Wars Outlaw》

《Star Wars Outlaw》是另一款原生支援 DLSS4 技術的遊戲,遊戲內「Frame Generation」選項同樣可設「4x」。
效能測試:
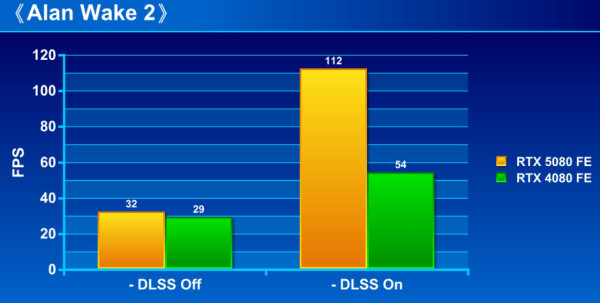
《Alan Wake 2》


《Alan Wake 2》「DLSS Frame Generation」選項。
效能測試:
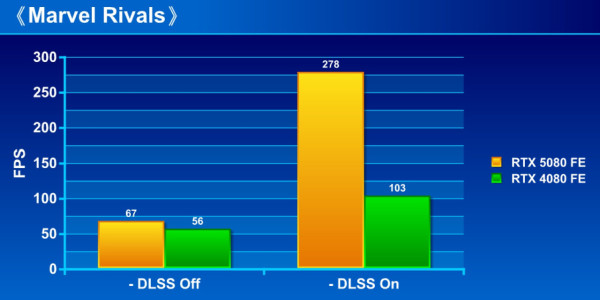
《Marvel Rivals》

效能測試:
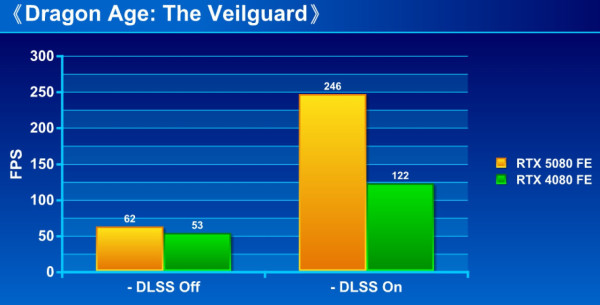
《Dragon Age: The Veilguard》

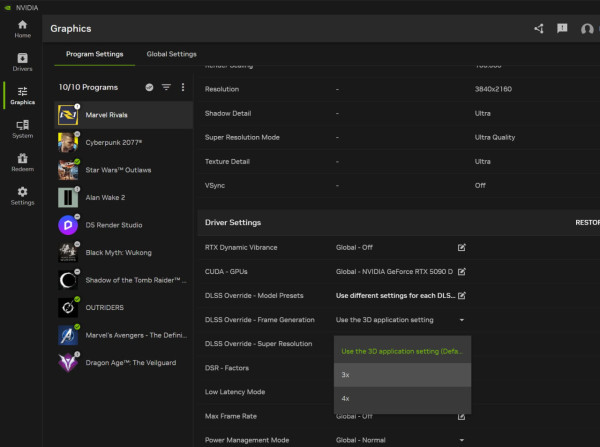
《Dragon Age: The Veilguard》需在 NVIDIA 應用程式內設定「DLSS Multi Frame Generation」。
效能測試:
分析:DLSS4 提速效果明顯
GeForce RTX 5080 FE 內建 第 5 代 Tensor Cores 進行「DLSS MULTI FRAME GENRATION 」,有效提升遊戲 FPS 流暢度。從測試可見,在未啟用 DLSS MULTI FRAME GENRATION 前,GeForce RTX 5080 FE 已能領先 RTX 4080 FE 約 10% 至 19%,而當啟用 DLSS MULTI FRAME GENRATION 技術,即進一步大幅拉開至領先 75% 至最高 160%,相當驚人。
《3DMark》 DLSS 測試
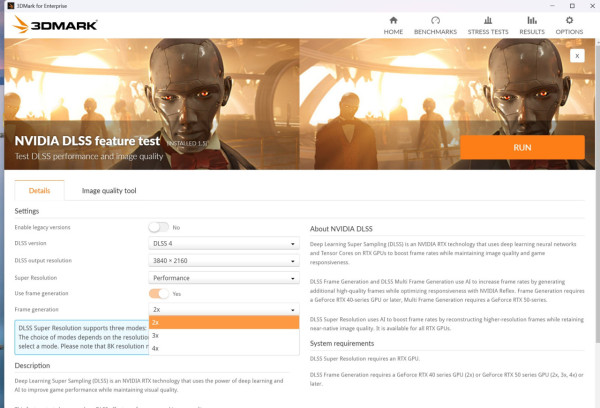
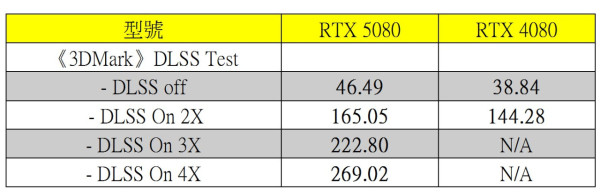
《3DMark》DLSS 4 測試 GPU 在使用不同 Frame Generation 設定的流暢度,測試可見 RTX 5080 FE 在啟用 2X、3X、4X Frame Generation 後,FPS 分別由 46.49 提升了 3 至 5 倍。
Test 03:AI 運算測試
NVIDIA Blackwell 新架構除了在遊戲效能提升,在 AI 運算表現也有大幅度的優化,ezone.hk 今次找來多款評估系統生成式 AI 模型性能的工具,測試 RTX 5080 FE 的 AI 運算表現。
《MLPerf-Client》測試
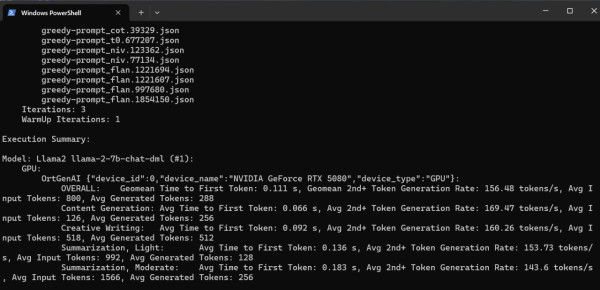
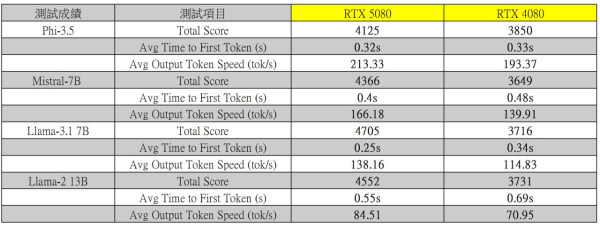
MLPerf-Client 測試是一項專門評估人工智慧和機器學習性能的基準工具,用於測試不同硬體在執行機器學習工作負載時的效能表現。該測試涵蓋各種應用場景,例如圖像分類、自然語言處理和推薦系統,模擬實際的工作需求,幫助硬體廠商和研究人員量化效能表現。MLPerf-Client 測試的設計重視公平性和可比性,適合用於比較不同 GPU 或 CPU 的機器學習運算效率,使用戶了解硬體在訓練與推理任務中的實際性能,提供選擇與優化建議。MLPerf-Client 測試會顯示吞吐量 (Throughput),以每秒處理的樣本數或請求數,例如每秒圖像分類數或每秒推薦系統推理數。
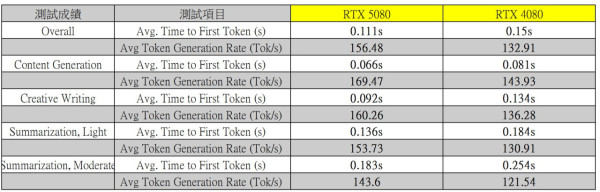
《UL Procyon AI Text Generation》測試
UL Procyon AI Text Generation 測試是一套專為評估生成式 AI 模型性能的工具,適用於主流的文字生成應用場景。此測試專注於分析大型語言模型(LLM)在不同硬體上的推理能力與效能表現,涵蓋內容生成、文本總結及創意寫作等真實使用情境。
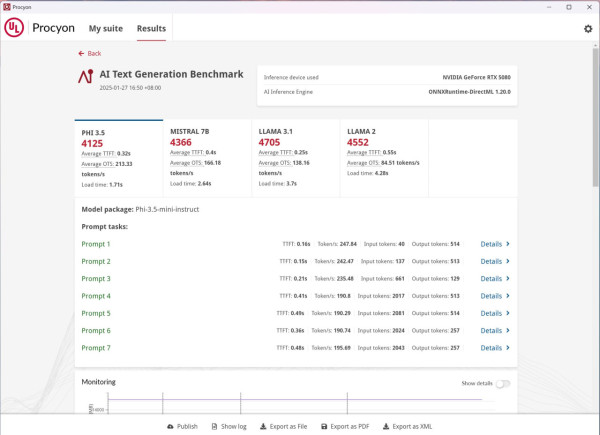
該工具支援多種生成式 AI 模型(如 Meta 的 Llama 2),並記錄關鍵性能指標,包括「生成第一個標記的時間」和「每秒生成後續標記的速度」。此外,測試兼容 Microsoft 的 ONNXRuntime-GenAI,允許模型在多種硬體環境下執行,並充分利用 DirectML 實現加速。UL Procyon AI Text Generation 測試為硬體性能評估提供了一種標準化的方法,使開發者能夠比較不同 GPU 的生成式 AI 工作負載表現,是評估硬體在生成式 AI 任務中效率的關鍵工具。
《UL Procyon FLUX.1 AI Image Generation Demo for NVIDIA 》
UL Procyon FLUX.1 AI Image Generation Demo for NVIDIA 是一款專為測試 NVIDIA 繪圖卡生成式 AI 性能設計的工具。該演示使用 FLUX.dev 模型,模擬高效能圖像生成的實際應用場景,特別是使用 NVIDIA 最新的 FP4 精度技術,大幅降低 VRAM 需求,同時保持高質量輸出。此工具評估 GPU 在處理複雜生成式 AI任務中的效能,提供準確的性能數據,幫助用戶了解硬體在創意設計與 AI 驅動工作負載中的表現。
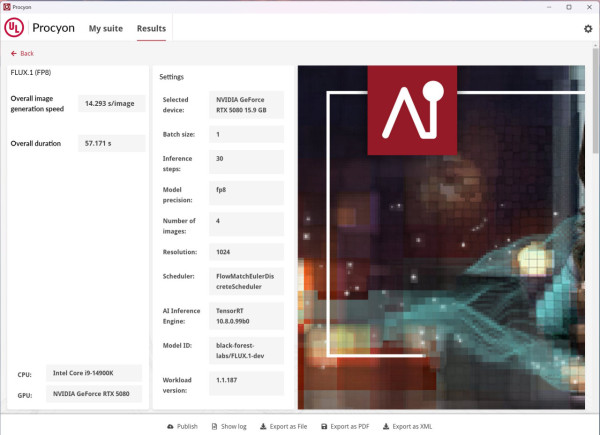
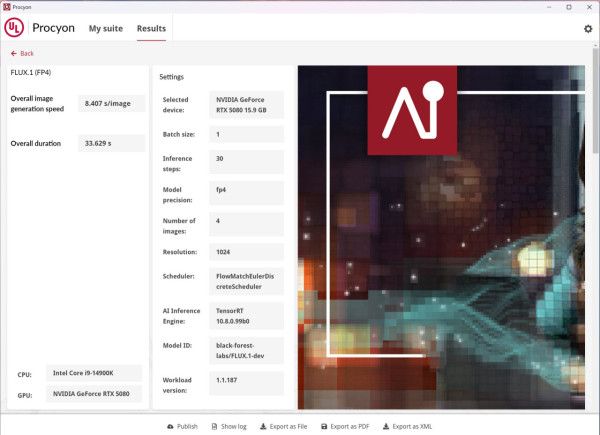

分析:AI 全面加速
從以上 AI 測試結果可見,NVIDIA GeForce RTX 5080 在 AI 運算方面展現了顯著的進步,主要得益於全新的 Blackwell 架構和第五代 Tensor Cores。這些改進使其在處理生成式 AI 和深度學習任務時的性能達到新高度。RTX 50 系列首次原生支援 FP4 精度,將模型運行效率提升約 2 倍,且顯著降低 VRAM 使用需求。第五代 Tensor Cores 提供高達 2.5 倍的 AI 運算性能,支持更快速的推理和訓練過程,尤其是在圖像生成、語言處理等任務中表現出色。此外,RTX 50 系列支持新一代 Transformer 模型,提升 AI 圖像穩定性、細節解析和運動畫面表現。同時,其能效比亦顯著提高,為用戶在生成式 AI、內容創作和科研應用中提供最佳解決方案,滿足高效能 AI 運算的需求。
評語:DLSS4 全面加速
GeForce RTX 5080 作為 RTX 50 系列第二位成員,利用新一代 Blackwell 新架構,在未有大幅增加 CUDA 數目及電晶體數目下,純以新架構已能提供不俗的效能提升,而在配合 DLSS 4 技術更是有極亮眼的表現,加上 NVIDIA 與各遊戲廠商一直合作無間,相信支援 DLSS4 技術的遊戲將不斷增加,使新 RTX 50 核心的威力盡現。
【精選消息】
Source: ezone.hk