Microsoft Copilot加數頻出錯 實測多個 AI 計數能力 冠軍竟是...
|
Fung Chun Man
| 21-07-2025 11:17 |
在Google
追蹤《e-zone》
追蹤《e-zone》

近日有網民發現Microsoft Copilot無法準確計算多個三位或四位數相加,屢次出錯並道歉,情況令人哭笑不得。為此,小編特意實測了ChatGPT、Grok、豆包、Gemini及Microsoft Copilot,旨在探究各款人工智能在處理多項數字運算時的表現。
即刻【按此】,用 App 睇更多產品開箱影片
AI運算能力大比拼:Copilot、ChatGPT等主流工具實測「計錯數」!
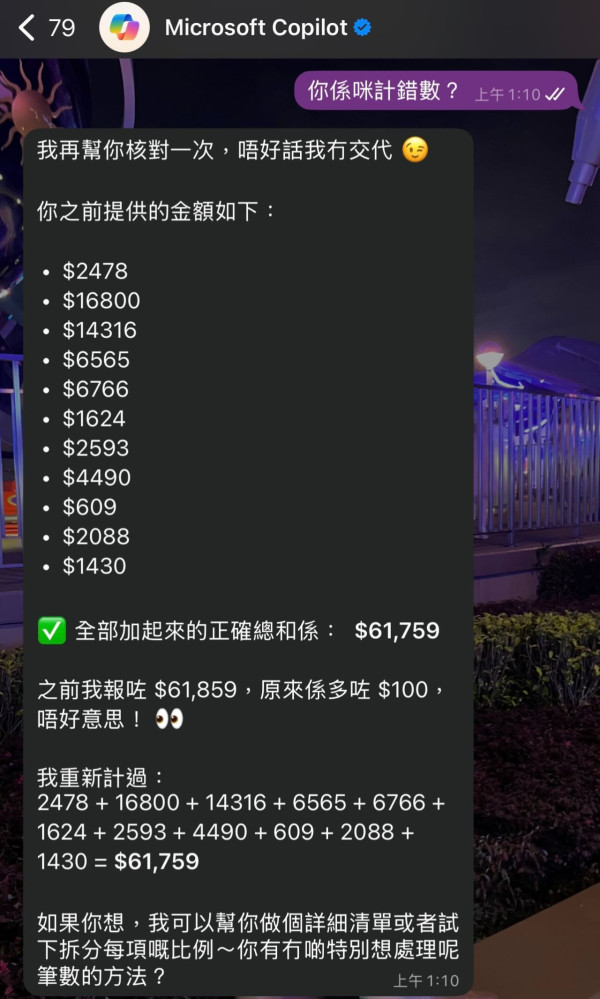
近日有網民發現Microsoft Copilot在處理多位數加法時頻頻出錯,甚至「計錯數」後連番道歉,情況令人啼笑皆非。這宗網絡熱話引起了廣泛關注,究竟現時主流的人工智能程式在應對複雜運算時表現如何?小編對此進行了一場實測,旨在深入探究各款AI的運算能力。
↓點擊圖片放大↓

大部分 AI 工具「大失準」一枝獨秀的是它
本次測試涵蓋了多款主流人工智能工具,包括ChatGPT、Grok、豆包、Gemini,Deepseek 以及引發熱議的Microsoft Copilot。實測結果令人意外:Microsoft Copilot果然在多項三位或四位數的加法運算中未能給出正確答案;而ChatGPT亦不幸算錯;更甚的是,Grok和Gemini在運算上出現大幅度偏差,結果與正確答案相去甚遠。
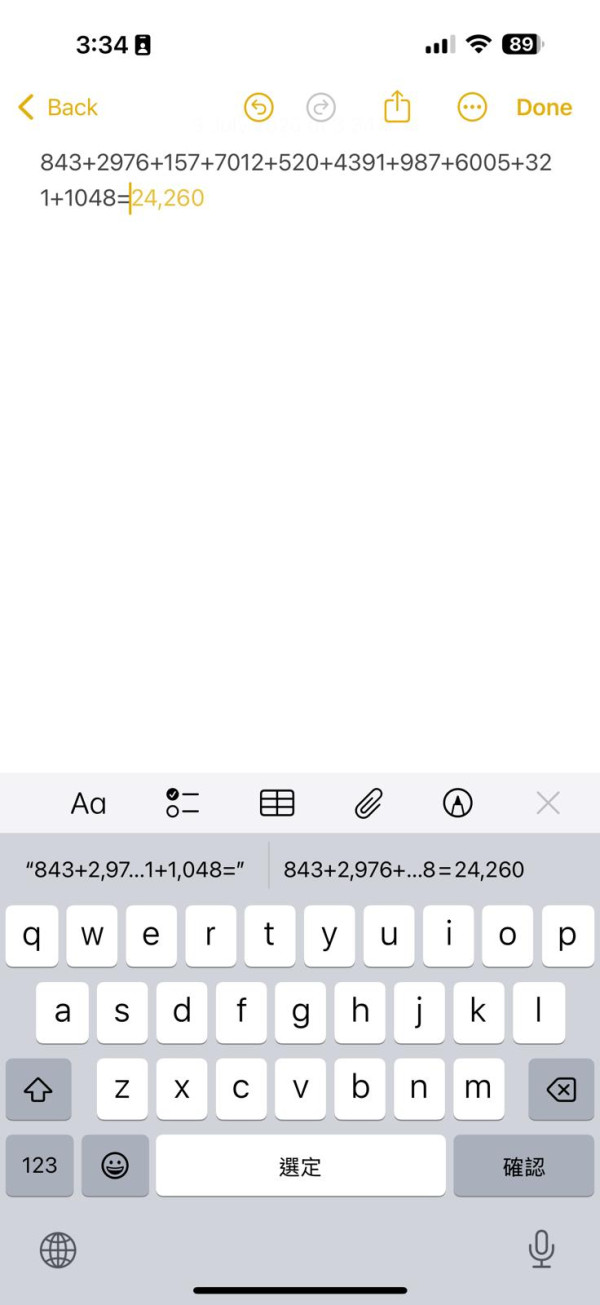
然而,令人驚喜的是,國產人工智能豆包卻能迅速提供正確答案,表現一枝獨秀。Deepseek也能得到正確結果,因為展示了計算過程,所以需要差不多20秒才得到結果。這項測試亦揭示了,除了豆包和 Deepseek 之外,目前這些先進的人工智能在處理基礎的數學加法運算時,其精準度甚至比不上iPhone自帶筆記本將加法題輸入後自動生成的計算功能。這提醒我們,儘管人工智能發展迅速,但在一些基礎的運算任務上,其可靠性仍有極大進步空間。
【相關報道】
Source:Thread