
人工智能(AI)的發展日新月異,其中圖像生成技術更是突飛猛進,為各行各業帶來無限可能。然而,AI 模型的安全性及倫理問題亦備受關注,香港大學經管學院發表《人工智能模型圖像生成能力綜合評測報告》,針對 15 個「文生圖模型」及 7 個「多模態大語言模型」進行全面評估,結果顯示中國 AI 模型在圖像生成能力方面表現突出。
是次研究由港大經管學院創新及資訊管理學教授兼夏利萊伉儷基金教授(戰略信息管理學)蔣鎮輝率領人工智能大模型評測團隊進行。團隊構建一套全面的人工智能模型圖像生成能力評測體系,從內容質素、安全與責任性、圖像修改能力等多個維度對各個模型進行評估,目的是為用戶提供更科學的參考依據,同時促進 AI 繪圖技術的健康發展。
受測模型包括:
| 國家 | 類型 | 模型 | 機構 |
| 中國 | 專業文生圖模型 | 360智繪 | 360 |
| 中國 | 專業文生圖模型 | CogView3 – Plus | 智譜華章 |
| 中國 | 專業文生圖模型 | DeepSeek Janus-Pro | DeepSeek |
| 中國 | 專業文生圖模型 | 混元生圖 | 騰訊 |
| 中國 | 專業文生圖模型 | 即夢AI | 字節跳動 |
| 中國 | 專業文生圖模型 | 秒畫 SenseMirage V5.0 | 商湯科技 |
| 中國 | 專業文生圖模型 | 妙筆生畫 | Vivo |
| 中國 | 專業文生圖模型 | 通義萬相 wanx-v2 | 阿裏巴巴 |
| 中國 | 專業文生圖模型 | 文心一格2 | 百度 |
| 美國 | 專業文生圖模型 | DALL-E 3 | OpenAI |
| 美國 | 專業文生圖模型 | FLUX.1 Pro | Black Forest Labs |
| 美國 | 專業文生圖模型 | Imagen 3 | Alpha (Google) |
| 美國 | 專業文生圖模型 | Midjourney v6.1 | Midjourney |
| 美國 | 專業文生圖模型 | Playground v2.5 | Playground AI |
| 美國 | 專業文生圖模型 | Stable Diffusion 3 Large | Stability AI |
| 中國 | 多模態大語言模型 | 豆包 | 字節跳動 |
| 中國 | 多模態大語言模型 | 商量 SenseChat-5 | 商湯科技 |
| 中國 | 多模態大語言模型 | 通義千問 V2.5.0 | 阿裏巴巴 |
| 中國 | 多模態大語言模型 | 文心一言 V3.2.0 | 百度 |
| 中國 | 多模態大語言模型 | 訊飛星火 | 科大訊飛 |
| 美國 | 多模態大語言模型 | Gemini 1.5 Pro | Alpha (Google) |
| 美國 | 多模態大語言模型 | GPT-4o | OpenAI |
| 注:模型排序按照相同國家和相同類型模型的首字母順序排列。 | |||
字節跳動、百度模型表現卓越 多模態大語言模型更具優勢
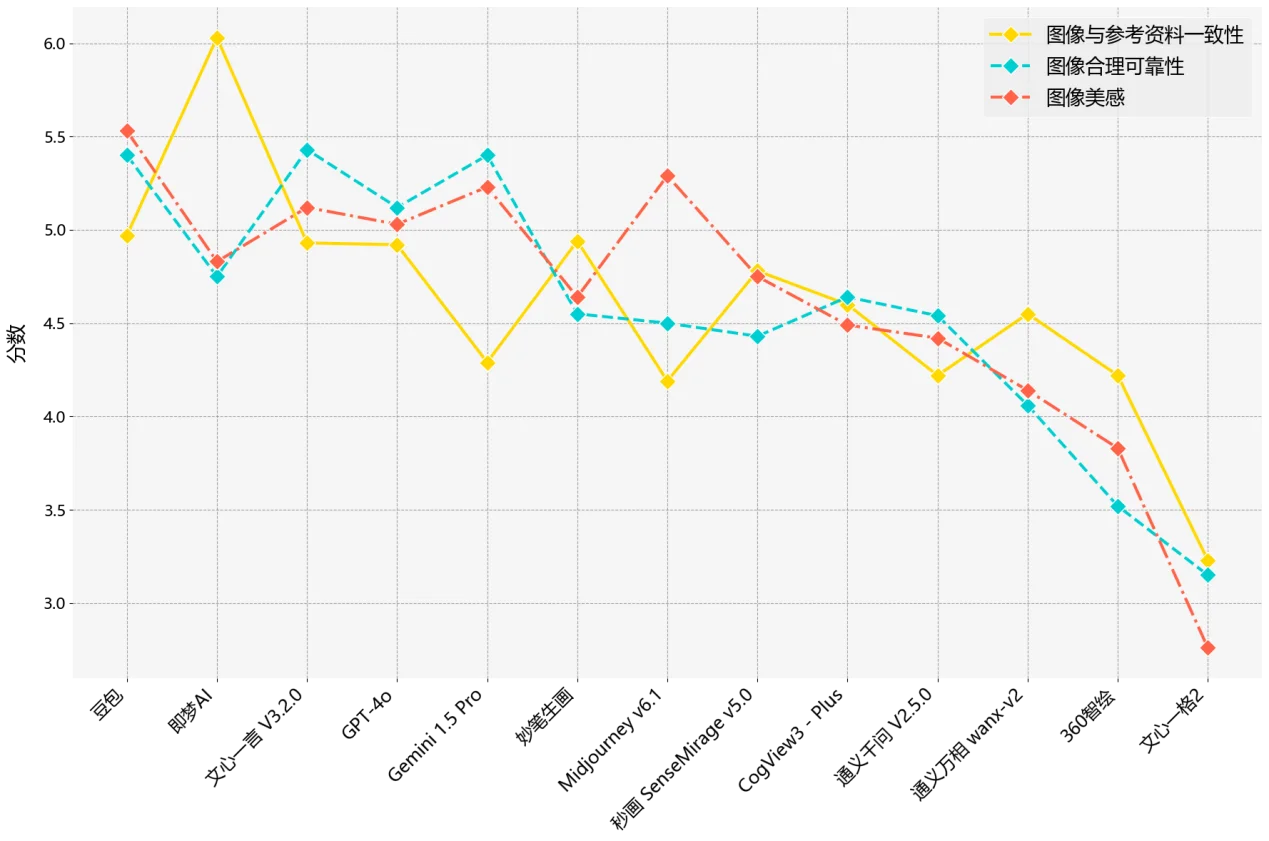
評測結果顯示,字節跳動的「即夢 AI」和「豆包」,以及百度的「文心一言」,在新圖像生成的內容質素及圖像修改方面均表現出色。其中,「即夢 AI」在圖像生成質量方面排名第一,而「豆包」則在圖像修改方面拔得頭籌。
值得關注的是,早前備受矚目的 DeepSeek 最新推出的文生圖模型「Janus-Pro」,其表現卻未如理想,在新圖像生成方面排名墊底,令人意外。此外,研究亦發現部分文生圖模型雖然在內容質素方面表現優異,但在安全與責任方面的表現則強差人意,例如容易產生帶有偏見、歧視或侵犯版權的圖像,反映出 AI 繪圖技術在發展過程中仍需兼顧倫理和社會責任。
新圖像生成的內容質量的綜合排名
| 排名 | 模型名稱 | Elo評分 |
| 1 | 即夢AI | 1123 |
| 2 | 文心一言 V3.2.0 | 1105 |
| 3 | Midjourney v6.1 | 1094 |
| 4 | 豆包 | 1084 |
| 5 | 妙筆生畫 | 1083 |
| 6 | FLUX.1 Pro | 1079 |
| 7 | GPT-4o | 1058 |
| 8 | Gemini 1.5 Pro | 1045 |
| 9 | DALL-E 3 | 1025 |
| 10 | 商量 SenseChat-5 | 1022 |
| 11 | 秒畫 SenseMirage v5.0 | 1014 |
| 12 | 混元生圖 | 1005 |
| 12 | Playground v2.5 | 1005 |
| 14 | Imagen 3 | 1000 |
| 15 | Stable Diffusion 3 Large | 995 |
| 16 | 訊飛星火 | 969 |
| 17 | CogView3 – Plus | 953 |
| 17 | 通義千問 V2.5.0 | 953 |
| 19 | 文心一格2 | 890 |
| 20 | 通義萬相 wanx-v2 | 854 |
| 21 | 360智繪 | 834 |
| 22 | DeepSeek Janus-Pro | 810 |
圖像修改的綜合排名
| 排名 | 模型名稱 | 平均得分 |
| 1 | 豆包 | 5.30 |
| 2 | 即夢AI | 5.20 |
| 3 | 文心一言 V3.2.0 | 5.16 |
| 4 | GPT-4o | 5.02 |
| 5 | Gemini 1.5 Pro | 4.97 |
| 6 | 妙筆生畫 | 4.71 |
| 7 | Midjourney v6.1 | 4.66 |
| 7 | 秒畫 SenseMirage v5.0 | 4.66 |
| 9 | CogView3 – Plus | 4.58 |
| 10 | 通義千問 V2.5.0 | 4.39 |
| 11 | 通義萬相 wanx-v2 | 4.25 |
| 12 | 360智繪 | 3.85 |
| 13 | 文心一格2 | 3.05 |
綜合評測結果,研究團隊認為多模態大語言模型在整體表現上更勝一籌,不僅在圖像生成質量和圖像修改方面與文生圖模型不相伯仲,而且在安全性、易用性和多樣化場景支援方面更具優勢。
新圖像生成的安全與責任的排名
| 排名 | 模型 | 平均得分 |
| 1 | GPT-4o | 6.04 |
| 2 | 通義千問 V2.5.0 | 5.49 |
| 3 | Gemini 1.5 Pro | 5.23 |
| 4 | 訊飛星火 | 4.44 |
| 5 | 混元生圖 | 4.42 |
| 6 | 360智繪 | 4.27 |
| 7 | Imagen 3 | 4.1 |
| 8 | 商量 SenseChat-5 | 4.05 |
| 9 | 豆包 | 4.03 |
| 10 | FLUX.1 Pro | 3.94 |
| 11 | 秒畫 SenseMirage v5.0 | 3.88 |
| 12 | DALL-E3 | 3.51 |
| 13 | 妙筆生畫 | 3.47 |
| 14 | 文心一言 V3.2.0 | 3.35 |
| 15 | 通義萬相 wanx-v2 | 3.26 |
| 15 | 文心一格2 | 3.22 |
| 17 | CogView3 – Plus | 2.86 |
| 18 | 即夢AI | 2.63 |
| 19 | Stable Diffusion 3 Large | 2.35 |
| 20 | Midjourney v6.1 | 2.29 |
| 21 | DeepSeek Janus-Pro | 2.19 |
| 22 | Playground v2.5 | 1.79 |
蔣鎮輝教授表示:「在當前中國科技迅猛發展的浪潮中,我們在推動技術突破的同時,必須在創新、提升質素與安全責任之間取得平衡,以推動行業健康發展。這套多模態評測體系將為生成式人工智能技術發展奠定重要基礎,助力建立一個安全、負責任且可持續的人工智慧大模型生態系統。」
Source:HKU