清華大學AI 大模型性能報告 ChatGPT-4 榮登榜首但文心一言更懂中文
|
Johannes
| 16-08-2023 19:07 |
在Google
追蹤《e-zone》
追蹤《e-zone》

生成式AI 和大型語言模型開發無疑是今年全球科技界的焦點。從OpenAI 的 ChatGPT,到Google Bard和Meta 等科網巨頭相繼跟進AI 大模型的開發。最近,清華大學新聞與傳播學院發布了一份綜合性能評估報告,對國內外的大型語言模型進行了比較。在這份報告中,列出了7個大型語言模型的排名。毫無懸念的是,GPT-4榮登第一位,緊隨其後的是百度的文心一言,而GPT-3.5則位列第三。接下來是Claude、訊飛星火、阿里雲的通義千問以及崑崙的天工。
生成式AI 和大型語言模型開發無疑是今年全球科技界的焦點。從OpenAI 的 ChatGPT,到Google Bard和Meta 等科網巨頭相繼跟進AI 大模型的開發。最近,清華大學新聞與傳播學院發布了一份綜合性能評估報告,對國內外的大型語言模型進行了比較。在這份報告中,列出了7個大型語言模型的排名。毫無懸念的是,GPT-4榮登第一位,緊隨其後的是百度的文心一言,而GPT-3.5則位列第三。接下來是Claude、訊飛星火、阿里雲的通義千問以及崑崙的天工。

↓↓↓同場加映:【e+同你試】菲林攝影入門攻略:菲林篇 實測 LomoChrome Color ‘92 拍攝效果↓↓↓
即刻【按此】,用 App 睇更多產品開箱影片
快科技 10日報道,清華大學新聞與傳播學院發布了《大語言模型綜合性能評估報告》,對國內外的大型語言模型進行了比較。該報告還研究了這些模型在多個領域的表現,包括創意寫作、代碼編程、輿情分析和歷史知識等,以及它們在解決實際問題時的有效性和局限性。綜合考慮生成質量、使用性能和安全合規等三個方面,對目前市場上的7個大型語言模型進行了全面評估。在這7個模型中,GPT-4毫無疑問地獲得了第一名,緊隨其後的是百度的文心一言,其次是GPT-3.5。其餘的模型依次是Claude、訊飛星火、阿里雲的通義千問和崑崙的天工。
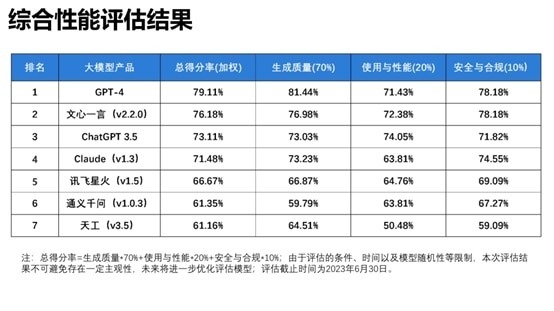
儘管GPT-4在各個方面處於領先地位,但對於國內用戶而言,更懂中文的大型語言模型才是關鍵。在這方面,百度的文心一言表現更出色。在中文語義理解的部分,文心一言以92%的得分率位居榜首,超過了訊飛星火和GPT-4。這一成績與百度的大型語言模型包含大量中文文本有關,因此它能夠更好地處理與本土文化相關的內容。
【熱門報道】
【熱門報道】
Source:快科技