AI神話破滅? 微軟、Uber因Token開支失控急煞 Nvidia高層承認:用AI貴過用人
|
Fung Chun Man
| 05-06-2026 12:57 |
在Google
追蹤《e-zone》
追蹤《e-zone》

全球企業積極導入AI工具,惟面臨沉重財務考驗。微軟因成本高昂而取消Anthropic旗下AI程式碼生成工具的使用授權;Uber亦於四個月內耗盡全年AI工具預算。雖然運算單位價格預期將大幅下降,但隨着AI代理興起,token總消耗量呈現爆發式增長,導致企業整體AI運算與推理成本不跌反升。
即刻【按此】,用 App 睇更多產品開箱影片
Token降價都冇用?黃仁勳狂推Token 微軟Uber卻因Token開支失控急煞停
呢幾年來全球各大企業積極導入AI工具,並鼓勵員工大量消耗運算資源(token)。輝達(Nvidia)執行長黃仁勳曾公開表示,頂尖工程師每年應花費價值達25萬美元的token,更向企業喊話「算力就是收入」,主張誰能多榨出token誰就贏。然而,這股全球AI熱潮正迎來現實的財務考驗。科技巨頭微軟(Microsoft)與出行平台Uber近期接連傳出因AI成本失控,被迫在相關政策上緊急煞車。
企業AI開支遠超預期 科技巨頭被迫暫停自由實驗
市場消息指出,微軟近期已著手取消Anthropic公司旗下AI程式碼生成工具「Claude Code」的使用授權,並引導內部工程師改為使用自家的GitHub Copilot CLI。值得注意的是,這距離微軟首次開放Claude Code權限、讓員工自由進行實驗,僅僅過了半年時間。


據悉,Claude Code在微軟內部的受歡迎程度遠超預期,員工極高頻率的使用率帶來了極其驚人的營運成本。這項沉重的財務負擔,最終促使這家科技巨頭不得不對自家工程師高度依賴的第三方工具祭出限制措施。
與此同時,Uber亦面臨相同困境。Uber科技長普拉文·內帕利・納加(Praveen Neppalli Naga)先前透露,公司內部採用AI的速度遠超預期,導致整個2026年度的AI程式碼工具預算,在短短四個月內便已被徹底燒光。

此現象反映出,過去市場預期利用AI替代或輔助人類員工以提升效益的美好想像,實際執行層面遠比早期評估更為複雜。企業甚至開始面臨「算力推理成本比員工薪水更貴」的全新通膨危機。
為什麼token價格大幅下降,企業整體AI運算成本卻不跌反升?
企業界此前普遍預期,隨著AI技術的演進與普及,運算token的單價將會持續下滑,進而推動企業生產力提升並降低整體成本。然而,市場調查機構顧能(Gartner)高級研究總監分析師威爾.索墨(Will Sommer)發出警告,企業不應單憑token單價下降,便盲目認為使用AI的總成本也會隨之下滑。
Gartner研究報告指出,預計到2030年,運行擁有一兆(1 Trillion)參數規模的超大型語言模型,其推理成本與2025年相比,確實將大幅銳減將近90%。然而,這並不等同於企業的AI總開支會同步下降。核心原因在於「AI代理」(AI Agent)消耗token的膨脹速度,遠超token價格的下降幅度,導致整體推理成本在抵銷降幅後依然持續上升。
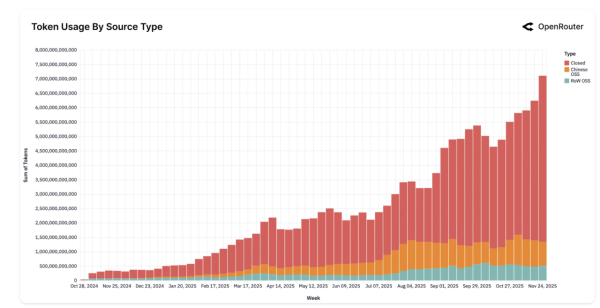
金融機構高盛(Goldman Sachs)的預測模型亦支持此觀點。高盛指出,在AI代理應用的推波助瀾下,到了2030年,全球企業與消費者的token總消耗量將呈現爆發式增長,暴增24倍,達到每月驚人的120千兆(120 quadrillion)個。這正是全球算力推理成本持續被推向新高的最核心因素。
企業養AI代理與人類員工,邊個成本更高?
儘管眾多科技巨頭的行政總裁仍持續描繪宏大的AI願景,例如黃仁勳近期便公開宣示,預期未來在輝達內部,每一位員工身旁都將有100個AI代理協同作業,但AI代理背後所伴隨的龐大運算成本,可能將令多數企業難以消受。
輝達應用深度學習副總裁布萊恩.卡坦扎羅(Bryan Catanzaro)對此坦承:「對我的團隊而言,運算成本已遠遠超過員工的成本。」
當全球頂尖、掌握核心AI晶片設計技術的專業團隊,都必須面對「養AI比養員工更貴」的現實時,這無疑為市場敲響了警鐘,也給那些盲目相信能依靠AI裁員來縮減開支,或試圖全面以AI取代人力的企業,帶來了關鍵的現實檢視。
在企業全面導入AI應用的背景下,精確管理算力資源已成為控制營運成本的關鍵。以下針對開發團隊與企業內部應用,提出3個有效減少Token消耗量的實化建議:
企業控制AI營運成本3貼士
1. 導入提示詞優化與動態動態截斷機制(Prompt Engineering & Dynamic Truncation)
很多時,AI模型消耗大量Token是由於輸入(Input Context)包含了過多冗餘資訊。企業應在系統後端建立統一的提示詞(Prompt)優化機制:
嚴格限制歷史對話長度: 在構建聊天機械人或AI代理(AI Agent)時,避免將所有歷史對話無限制地傳送給模型。應採用滑動窗口(Sliding Window)或僅保留最近3至5輪的核心對話。
精簡上下文與知識庫檢索: 在使用RAG(檢索增強生成)技術時,限制向量資料庫返回的文檔片段數量與字數,只擷取與問題最相關的精準段落,避免將整篇冗長文檔塞入Prompt。
2. 實施任務分流與在地化輕量模型部署(Model Routing & SLM Deployment)
並非所有工作都需要動用擁有一兆參數規模的旗艦級超大型語言模型。企業應建立「智能路由分流」機制:
任務分級制: 對於簡單的資料格式化、程式碼除錯、文字摘要或日常客服等常規任務,應分流至參數較小、Token單價極低的輕量級模型(Small Language Models, SLMs),甚至是企業內部自行託管的開源模型。
高階模型專用化: 只有在處理涉及複雜邏輯推理、架構設計或跨領域深度分析時,才將請求導向如 Claude 或 GPT 的高階旗艦模型,從源頭降低高昂推理成本的發生率。
3. 優化AI代理的自我迴圈與結構化輸出(Agentic Loop Control & Structured Output)
AI代理(AI Agent)之所以會成為「Token吞噬者」,主要是因為其具備自主規劃與反思能力,容易在後端執行無效的「自我思考」或陷入無限迴圈:
設定最大反思與調用次數限制: 為AI代理的「思考步驟(Reasoning Steps)」和工具調用(Tool Calling)次數設立硬性上限(例如最多循環3次),防止代理程序在解題失敗時瘋狂重試,燒光預算。
限制結構化輸出格式: 在API請求中明確指定精簡的輸出格式(如 JSON 或特定的語法結構),要求模型「精準答題」,防止AI生成過多修飾性的客套話或冗長解釋,從而節省輸出端(Output)的Token開支。
Source: ezone.hk、bnext
【相關報道】
【相關話題】【Gemini用量改制】發送1指令竟耗盡5小時額度?Gemini使用上限縮水惹爭議 教你5招秘技大幅節省Token
Google 於本月的 Google I/O 2026 大會宣布調整 Gemini 用量上限,從過去單純的「指令次數」調整為「Token 實際運算量」以扣除額度。雖然文字問答、圖片生成、Deep Research 及影音生成的算力消耗本就不同,按運算量計費似乎更合理,但對用戶而言,現在極難預測每次發送訊息會吃掉多少配額。 不少用家亦抱怨現在只用一下子便直接爆額,甚至有網民分享,自己僅輸入一條影片生成的指令,Gemini 的 5 小時用量額度直接飆升,引起科技界廣泛討論。

Source: ezone.hk