Google「Nano-Banana」真身解密 實測Gemini 2.5 Flash Image 4 大優勢【附簡易教學】
|
Fung Chun Man
| 02-09-2025 15:19 |
在Google
追蹤《e-zone》
追蹤《e-zone》

AI 界最近掀起一場「奈米香蕉」(Nano-Banana)旋風,Google 現已證實其真身為新一代多模態 AI 模型 Gemini 2.5 Flash Image。這款被譽為「Photoshop 殺手」的工具,主打極速圖像生成與編輯,其核心優勢在於整合了多圖融合、角色風格一致性、對話式編輯及原生世界知識,讓創作過程更流暢。文章將深入分析此模型的四大核心能力,並比較其與 Midjourney 及 DALL-E 3 等競品的異同。
即刻【按此】,用 App 睇更多產品開箱影片
「Nano-Banana」真實身份:Gemini 2.5 Flash Image
最近在 AI 圈子裡「Nano Banana」(奈米香蕉)這個名字引發了廣泛討論,其出色的圖片編輯能力甚至讓它贏得了「Photoshop 殺手」的稱號。

現在 Google 已經正式證實,它就是 Gemini 2.5 Flash Image 的非官方代號。Gemini 2.5 Flash Image 是 Google 最新推出的多模態 AI 模型,它專注於圖像生成與編輯,並以其卓越的速度和精準度著稱。這個模型繼承了 Gemini 系列強大的多模態能力,能夠同時理解文字和圖像,讓用戶用更直覺、更自然的方式來創作和修改圖片。

功能詳解:四大核心能力與應用潛力
Gemini 2.5 Flash Image 最大的突破在於其對「視覺工作流」的重塑,它將以往割裂的圖像生成與編輯環節,透過四大核心能力無縫整合為一個流暢的對話式體驗。
多圖融合(Multi-image fusion)
傳統模型通常只能基於單一提示詞或單一參考圖像來生成內容。而 Gemini 2.5 Flash Image 能理解並融會多個輸入圖像的能力。例如,使用者可以將不同的產品圖像拖放到一個新的場景中,並透過一個簡單的提示詞,讓模型將這些元素無縫融合,創建出一個全新的、寫實的統一視覺。



角色與風格一致性(Character & Style consistency)
在圖像生成領域,要確保一個角色或物件在不同場景、不同動作中的外觀保持一致,是一項巨大的技術挑戰,常需要耗時的手動微調。Gemini 2.5 Flash Image 則能可靠地維護角色的視覺身份,讓使用者能將同一個角色置於不同環境,或從多個角度展示單一產品,同時保持其核心視覺特徵。



對話式編輯(Conversational editing)
該模型將圖像編輯從繁瑣的軟體操作(如筆刷、圖層選擇)中解放出來。使用者可以透過自然語言進行精準的局部或全域修改。例如,一個簡單的指令如「模糊背景」、「移除T恤上的污漬」或「改變人物的姿勢」就能完成原本需要專業設計軟體才能實現的操作。這種能力將創作過程從單一、靜態的生成,變為一個動態、多輪的「創意對話」,讓使用者能夠透過持續的互動,快速反覆運算,直到獲得滿意的結果。



原生世界知識(Native world knowledge)
與許多專注於美學生成的模型不同,Gemini 2.5 Flash Image 受益於 Gemini 家族強大的語義理解能力 。這使得它不僅僅是根據像素來生成圖像,更能理解圖像背後的深層含義和現實世界的邏輯。



顛覆性編輯技術不「走樣」 實用性強
Gemini 2.5 Flash Image 其出色的連貫性對於數碼創作者而言,無疑是一大福音。用戶在進行一連串編輯時,例如為相中人物更換背景或服飾,再也不用擔心主體會「走樣」或出現面部扭曲等問題。

實際應用場景
即時圖像編輯: 例如,讓使用者用自然語言來修改圖片,像是「把這張照片的背景換成海灘」。對於零售商、廣告商或內容創作者來說意義重大,能夠在不進行昂貴實體攝影的情況下,快速生成產品廣告圖、視覺化培訓材料或複雜的廣告視覺。
圖片多次編輯:動態、多輪的「創意對話」,讓使用者能夠透過持續的互動,快速反覆運算,直到獲得滿意的結果
創意內容生成: 編輯技術不「走樣」對於需要大規模生產品牌資產、系列漫畫或一致性廣告視覺的企業而言,能大幅提高生產力。
理解與學習新知識: Gemini 2.5 Flash Image 受益於 Gemini 家族強大的語義理解能力。這使得它不僅僅是根據像素來生成圖像,更能理解圖像背後的深層含義和現實世界的邏輯。例如:學生拍下教科書上的圖片或圖表,模型能即時解釋相關概念或提供更多資訊。
與 Midjourney、DALL-E 3 等頂級競品比較

在當前的圖像生成市場中,Midjourney 以其獨特的藝術風格和夢幻視覺聞名,而 DALL-E 3 則以其對提示詞的忠實理解和精確執行而著稱。Gemini 2.5 Flash Image 的市場定位則與這兩者有所不同,它不旨在成為最純粹的藝術創作者,而是專注於滿足日常創作者和企業對「可控性」與「生產力」的需求。
Flash Image 的核心競爭力在於其獨特的「思維推理層」(reasoning layer)。與 DALL-E 或 Midjourney 僅僅解釋提示詞不同,Flash Image 會先對請求進行深層次的思考與理解。這項能力使其在複雜的多步驟任務中表現更為可靠與準確,提供了更高的可重複性,這對於需要精準控制的商業應用至關重要。
Gemini 2.5 Flash Image vs. 主要競品功能與特性對比
比較方向 |
Gemini 2.5 Flash Image |
DALL-E 3 |
Midjourney |
核心優勢 |
強大的「思維」推理層,優化工作流,高度可控 |
高度忠實於提示詞,與 ChatGPT 深度整合,易於使用 |
獨特的藝術風格,擅長創造夢幻、電影般的視覺效果 |
圖像品質 |
SOTA 級別的生成與編輯品質,強調寫實與精準 |
忠實且精確,適合需要嚴格控制細節的場景 |
風格強烈、藝術性高,適合純粹的藝術創作與敘事 |
對話式編輯能力 |
強項。透過自然語言進行精準、多輪的編輯,實現迭代式創作 |
支援,但功能相對有限,不如 Flash Image 流暢與互動 |
支援,需配合使用 Vary Region 等進階編輯工具 |
角色一致性 |
具備強大的角色一致性能力,可跨多個提示維持主體外觀 |
隨提示詞長度變化,一致性可能減弱 |
支援角色參考(Character Reference),表現優異 |
世界知識/推理 |
內建 Gemini 世界知識,能理解手繪圖與複雜語義 |
依賴於 GPT 的強大語義理解能力 |
偏重視覺風格,語義理解相對較弱 |
易用性/工作流 |
深度整合於 AI Studio/Vertex AI,提供「單一堆棧」解決方案 |
深度整合於 ChatGPT,介面直觀,易於新手上手 |
主要透過 Discord 平台運作,現已推出網頁版 |
已知局限 |
小臉部細節與文字仍有失真,風格偶有「過度拋光」現象 |
在複雜提示下可能產生不連貫性 |
缺乏對話式編輯,需要精確的提示詞與參數控制 |
對比其他模型優勢
圖像編輯效能領先
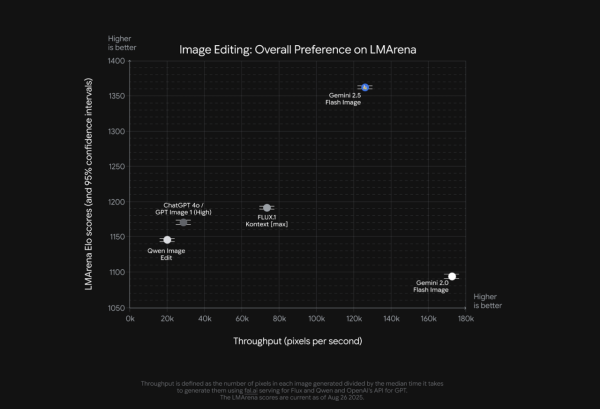
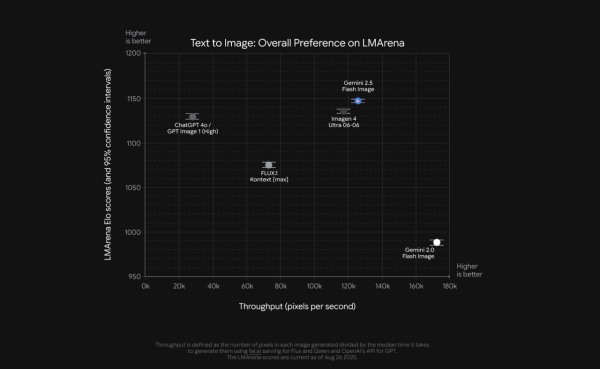
在圖像編輯能力方面,Gemini 2.5 Flash Image 在「LM Arena Elo 分數」和「吞吐量」這兩項指標上都處於領先地位。這意味著該模型不僅能以極高的品質進行圖像編輯,其速度也遠超過其他競爭對手,綜合表現最佳。
多維度評測全面領先
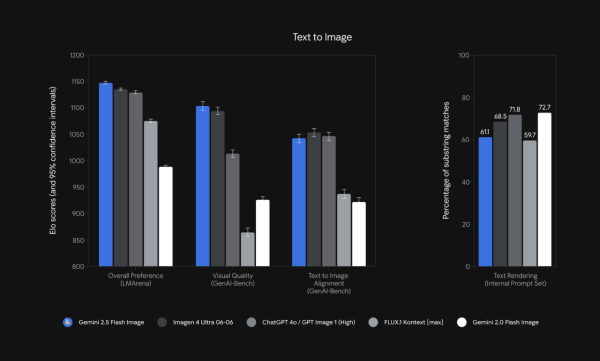
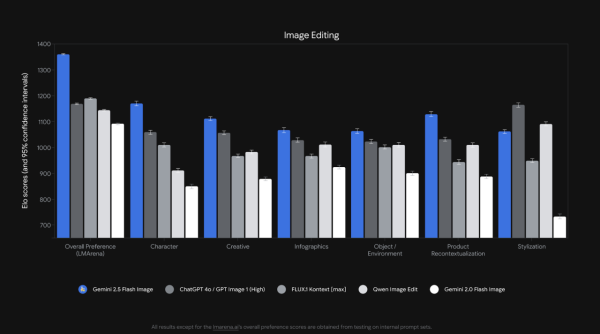
這張圖顯示,在多個評估指標上,Gemini 2.5 Flash Image 都展現了其優勢。
整體偏好 (LM Arena): 在使用者綜合偏好方面,Gemini 2.5 Flash Image 取得了最高的 LM Arena Elo 分數,領先所有競爭對手。
視覺品質 (GenAI-Bench): 在專門評估視覺品質的測試中,Gemini 2.5 Flash Image 也表現最佳,其 Elo 分數明顯高於其他模型。
文字與圖像對齊 (GenAI-Bench): 在確保生成圖像符合文字描述的準確性方面,Gemini 2.5 Flash Image 與 Imagen 4 Ultra 06-06 表現相近,都處於領先群。
文字渲染 (內部提示集): 在文字渲染的準確性測試中,Gemini 2.5 Flash Image 以高達 72.7% 的子字串匹配率,大幅領先其他模型,顯示其在處理圖像中文字方面的卓越能力。
免費體驗 Gemini 2.5 Flash Image 使用教學
想親身體驗 Gemini 2.5 Flash Image 的強大功能?其實步驟非常簡單,用戶可以透過以下方法免費使用:
1. 登入 Google Account: 首先,用你的 Google Account 登入 Gemini 平台。
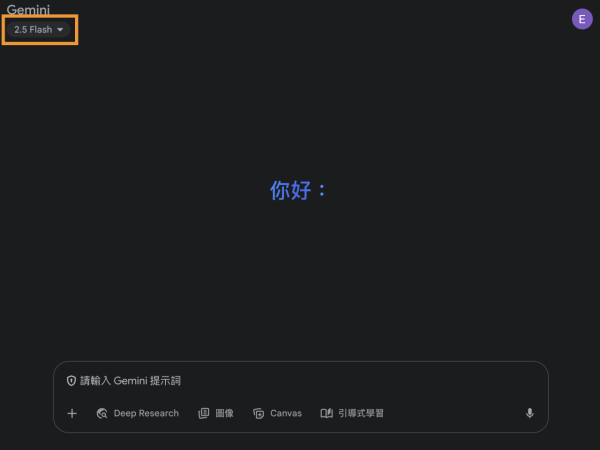
2. 選擇 Gemini 2.5 Flash: 登入後,在左上角選擇「2.5 Flash」,因為 Gemini 2.5 Flash Image 的功能已經全面整合在其中。
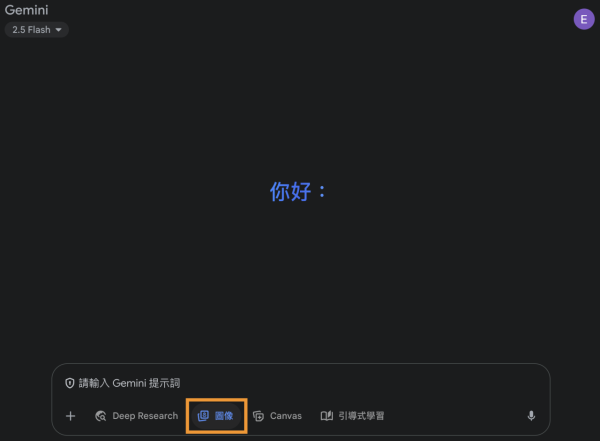
3. 開啟圖像功能: 之後,只需開啟下方的「圖像」(Image)功能,即可免費啟動 Gemini 2.5 Flash Image 的所有編輯能力。
Gemini 2.5 Flash Image常用功能
功能1:更換人物背景
使用者只需上傳圖片,並在對話框中輸入指令,例如「圖片生成:將背景換成外太空,2名女仔在銀河上跑步」,即可將原本在陸地跑步的兩位女性,無縫轉換到銀河中的太空場景。這項功能簡化了過去繁瑣的編輯步驟,讓專業設計師與一般使用者都能輕鬆實現創意,並透過精準的自然語言指令,大幅提升圖像編輯的效率與可能性。



功能2:將多張圖片結合
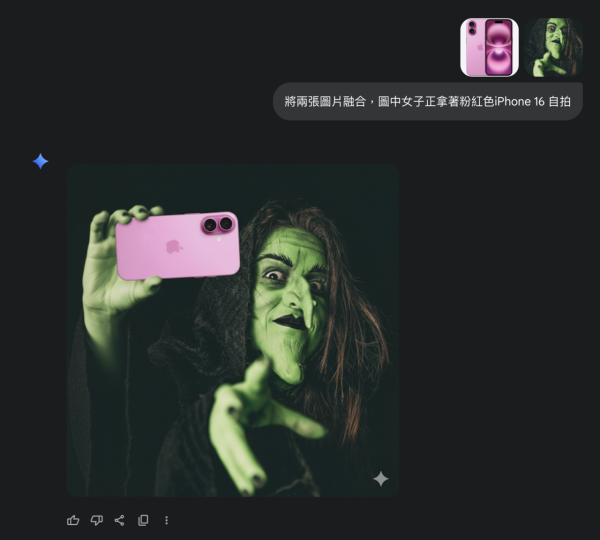
輸入這樣的指令:「將兩張圖片融合,圖片中的女子正在用粉紅色iPhone自拍」。這個指令能讓AI生成一張融合了女巫與iPhone的新圖片,並且動作會十分自然,讓女巫看起來真的像是拿著手機在自拍。
不過,Gemini 2.5 Flash Image 在細節處理上仍有進步空間。生成的圖片中,可能出現原圖中不協調的手部或多餘的肢體,影響整體視覺。這時,你可以透過進一步的指令來調整。例如,使用「請把多餘的手消除」這類的指令,就可以修飾畫面,讓最終的圖片看起來更加完美。



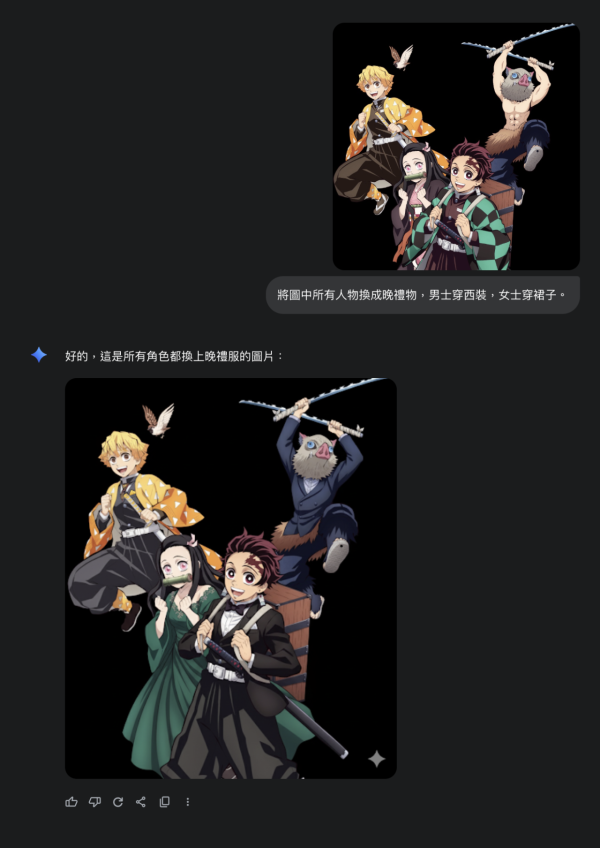
功能3:多次對話編輯圖片,更換元素
嘗試輸入指令:「將圖中人物的衣服都換成晚禮服,男士穿西裝,女士穿裙子」。這次的實驗中,角色成功換上華麗晚禮服與西裝,新服裝與人物身形比例協調,毫無違和感。

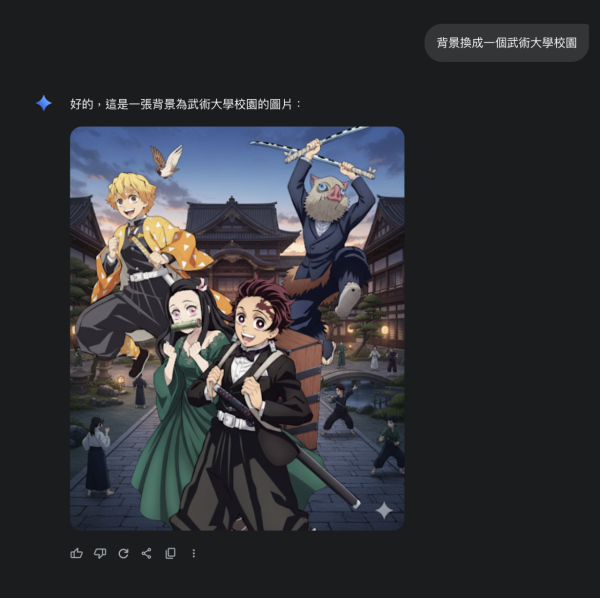
加入一個武術大學背景
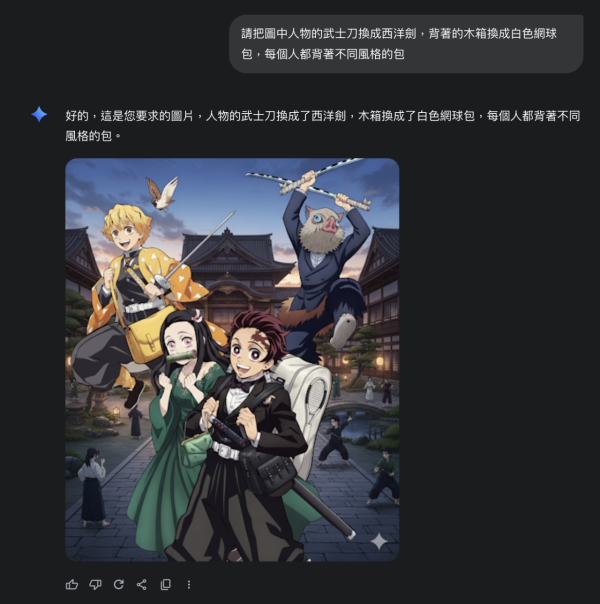
更換人物身上的物品元素搭配,如把木箱替換成白色網球包
添加新的元素,如戴上太陽眼鏡。
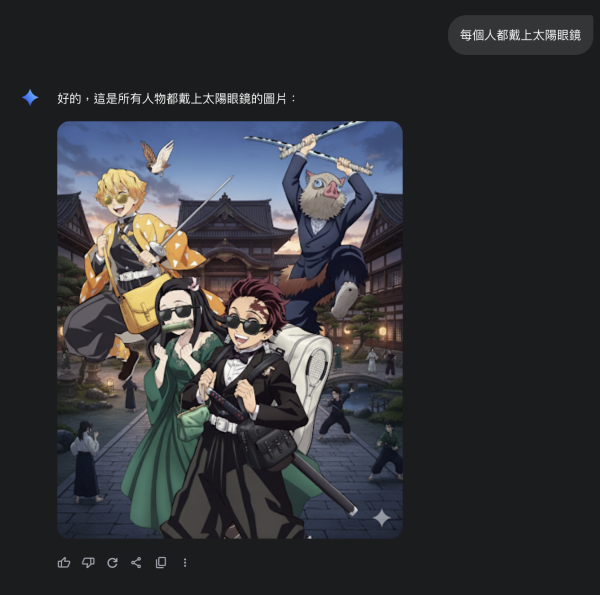
生成不同風格圖片
你只需要上傳一張自己的照片,並輸入簡單指令,例如:「生成CV照,要求專業且令人信服」。Gemini 2.5 Flash Image 便會根據指令,自動為你更換服裝與背景,優化光線與神情,最終生成一張符合專業需求的履歷照片。這項技術不僅省時省力,更能依據你的需求,生成多種風格的照片。無論是正式商務風、創意生活照,還是其他風格,你都能輕鬆透過指令獲得。



香港用戶如何毋須 VPN 照樣使用 Gemini 2.5 Flash Image?
由於部分地區如香港,用戶需要透過 VPN 才能使用 Gemini,這可能會對部分用戶造成不便。但好消息是,用戶可以透過第三方平台如 LMArena 使用 Gemini 2.5 Flash,這樣就不再需要 VPN 輔助了。透過這類平台,香港用戶也能輕鬆享受到 Gemini 2.5 Flash Image 所帶來的圖像編輯體驗。
使用方法點擊此連結
Source:ezone.hk
【相關報道】
【相關話題】免費生成大熱AI模型圖 無須VPN附生成Prompt指令 1優點更勝Gemini?
近期,大家都可能在社交平台上見到不少網民試玩真人AI模型圖,相當逼真細緻!除了Google Gemini外,其實還有一個AI工具可以生成同樣效果的圖片,而且有一點可能更勝Gemini!即刻睇睇試玩教學啦!
Source: ezone.hk
【相關話題】輕鬆教學 Microsoft Copilot 3D免費玩!2D變3D模型超簡單
Microsoft 最近在 Copilot Labs 推出免費的「Copilot 3D」功能,讓用家能輕鬆將 2D 圖像轉化為 3D 模型。這項新工具旨在降低 3D 創作的門檻,讓設計、遊戲及數碼藝術等領域的創作者,簡單上傳圖片,即可快速生成 3D 模型,並支援下載作 3D 打印,為用家帶來極大便利。
Source: ezone.hk