AI 工具轉會 Gemini 教學 一文睇清ChatGPT/Perplexity/DeepSeek/Grok/豆包記憶遷移步驟
|
Fung Chun Man
| 31-03-2026 15:34 |
在Google
追蹤《e-zone》
追蹤《e-zone》

Google 於 2026 年首季為 Gemini 推出「記憶與對話移轉」功能,打破 AI 平台間的數據壟斷。用戶現可將 ChatGPT、Perplexity、DeepSeek、Grok 及豆包等工具的歷史對話、個人偏好及工作流邏輯,透過標準化提示詞與 ZIP 檔案無縫遷移至 Gemini 生態系統。Ezone.hk 深入解析其雙軌數據吸納技術、超長上下文視窗應用及各平台的具體導出教學,助專業用戶實現 AI 數位資產的跨平台整合。
即刻【按此】,用 App 睇更多產品開箱影片
AI 工具記憶移轉至 Gemini 教學:ChatGPT/Perplexity/DeepSeek/Grok/豆包懶人包
全球 AI 生態大遷徙
在 AI 市場中,用戶與 AI 助手之間的關係已演變成一種深度的夥伴關係。用戶在單一平台上累積的對話紀錄、專業偏好、工作流邏輯及個人背景資訊,構成了所謂的「數位記憶」。然而,這種記憶長期以來被困在各個平台的「圍牆花園」(Walled Gardens)中,使用戶不易於轉換平台 。針對這一需求,Google 在 2026 年第一季對 Gemini 進行了戰略性升級,正式推出「記憶與對話移轉」(Import Memory and Chats)功能,旨在打破平台鎖定,讓用戶能夠將分散在 ChatGPT、Perplexity、DeepSeek、Grok 及豆包等工具中的數據資產,遷移至 Gemini 生態系統 。


這項舉措不僅是技術上的突破,更是 Google 在 AI 領土爭奪戰中的一次「大進攻」。通過提供標準化的數據提取提示詞(Prompt)與大容量 ZIP 檔案上傳機制,Google 實際上是在要求其競爭對手將最核心的用戶數據「打包送出」。對於香港及全球的專業用戶而言,這意味着個人 AI 助手的連續性不再受限於單一供應商。本文將深入解析這一場 AI 記憶大遷徙的技術路徑、操作細節及對未來數位生活的深遠影響。
第一章:Gemini 記憶移轉的核心技術機制
雙軌並行的數據吸納路徑
Gemini 的遷移系統設計邏輯在於將「抽象的個人化偏好」與「具體的歷史對話事實」分離處理。這種雙軌制確保了新模型既能繼承用戶的語氣與習慣,也能檢索到三年前的專案細節 。
| 遷移機制 | 技術原理 | 數據承載量 | 核心功能 |
| 記憶提取 (Memory Import) | 利用高度工程化的提示詞,驅動原 AI 模型自我總結用戶畫像。 | 約 1,500 至 5,000 Token 的純文字。 | 轉移身份、偏好、職業背景及運作規則 。 |
| 對話批次導入 (Bulk Chat Import) | 接受原平台導出的原始數據包(如 JSON/HTML),進行向量化處理。 | 單個 ZIP 檔案上限 5 GB,每日限 5 個檔案 。 |
建立長期的、可檢索的歷史知識庫 。 |
超長上下文視窗與 Context Caching 的角色
Gemini 1.5 Pro 與最新的 3.1 版本之所以能處理海量的外部導入數據,歸功於其高達 100 萬至 200 萬個 Token 的上下文視窗 。在遷移過程中,這意味着用戶不需要對過去幾年的對話紀錄進行大幅度刪減。模型具備「一次性閱讀」數千頁文字的能力,並能在其中尋找極其細微的關聯 。
此外,為了降低頻繁檢索大規模導入數據帶來的延遲與成本,Google 引入了上下文緩存(Context Caching)技術 。當用戶將某個大型專案的歷史紀錄導入後,系統會將這些數據預先處理並存儲在緩存中,後續提問時,系統只需支付約 10% 的 Token 成本,即可實現極速響應 。

第二章:ChatGPT 支援記憶數據精準導出
官方數據導出流程解析
ChatGPT 作為全球用戶基數最大的平台,其提供的數據導出功能是遷移工作的起點。OpenAI 根據 GDPR 等法規,允許用戶請求一份包含所有對話、自定義指令及帳號資訊的副本 。

進入設定介面:在 Web 端的左下角點擊個人頭像,選擇「Settings」。
數據控制操作:點擊「Data Controls」,在「Export Data」一欄點擊「Export」並確認 。
郵件領取連結:系統會在數分鐘至數天內(視數據量而定)發送下載連結至電子信箱。需注意該連結在 24 小時後失效 。
該 ZIP 包內包含 conversations.json。雖然 JSON 格式包含大量機器元數據(Metadata),但 Gemini 的導入器已針對此格式進行了優化,能夠自動過濾掉冗餘的 ID 標籤,僅提取對話文本 。
自定義指令與 Memory 功能的提取
除了歷史對話,ChatGPT 的「Memory」功能記錄了用戶的顯性與隱性偏好。要將這些記憶轉移至 Gemini,用戶需使用 Google 提供的標準提示詞(Prompt)。
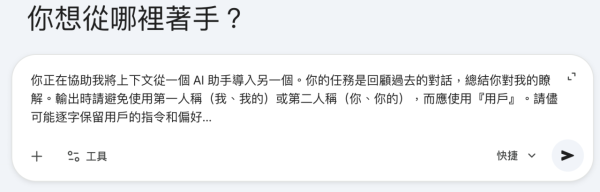
Gemini 官方建議的提取提示詞:
「你正在協助我將上下文從一個 AI 助手導入另一個。你的任務是回顧過去的對話,總結你對我的瞭解。輸出時請避免使用第一人稱(我、我的)或第二人稱(你、你的),而應使用『用戶』。請儘可能逐字保留用戶的指令和偏好...」 。
提取後的結果應包含:
人口統計資訊:姓名、職業、教育程度、居住地。
興趣與偏好:長期關注的主題、工作風格、對特定長度的偏好。
指令規則:明確要求的「Always do X」或「Never do Y」指令 。

將上述總結複製後,前往 Gemini 的「Settings & help」->「Import memory to Gemini」介面,將文字貼入即可讓 Gemini 立即學會你的所有工作習慣 。
第三章:Perplexity 支援單個導出 批次導出需要插件
處理研究線索(Threads)的特殊性
Perplexity AI 的價值在於其搜索脈絡與來源追蹤。用戶在 Perplexity 中累積的數據通常以「Threads」形式存在,每個 Thread 都是一個獨立的研究專案 。
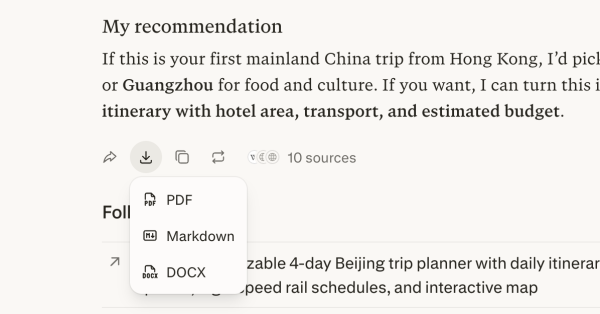
1. 個別導出法:在每個 Thread 的介面中,用戶可以點擊「Export」按鈕,選擇導出為 PDF 或 Markdown 。
2. 批次處理插件:對於擁有大量研究紀錄的用戶,建議使用「Perplexity to Notion」等 Chrome 擴展程序 。這些工具能將所有 Threads 批次同步至 Notion,隨後用戶可將 Notion 頁面打包為 Markdown 檔案,再上傳至 Gemini 。
研究源與關聯問題的繼承
遷移 Perplexity 數據時,最關鍵的是保留「Sources」(來源)與「Related Questions」(相關問題)。Gemini 在吸納這些 Markdown 數據時,會建立一個內部的引文索引 。這意味着當用戶在 Gemini 中繼續該研究時,Gemini 能夠識別出之前的參考來源,並根據之前的追蹤問題路徑提供進一步的深度分析 。
第四章:DeepSeek 一鍵導出數據成壓縮包
技術導向數據的 JSON 解析
DeepSeek 在亞太地區及技術圈擁有大量忠實用戶,其導出的數據通常包含大量複雜的代碼塊與邏輯推理紀錄 。
1. 導出操作:在 DeepSeek Web 端,通過「Settings」->「Data」->「Export data」路徑獲取對話壓縮包 。
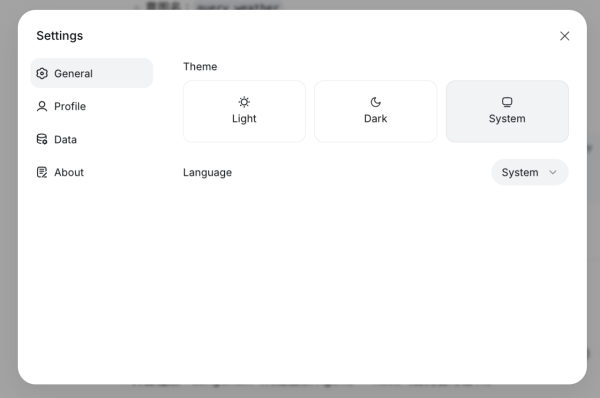
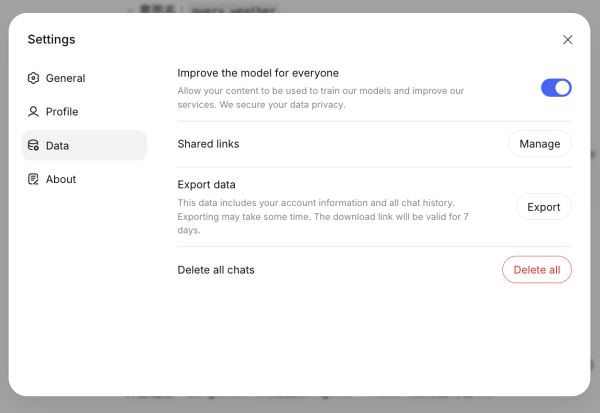
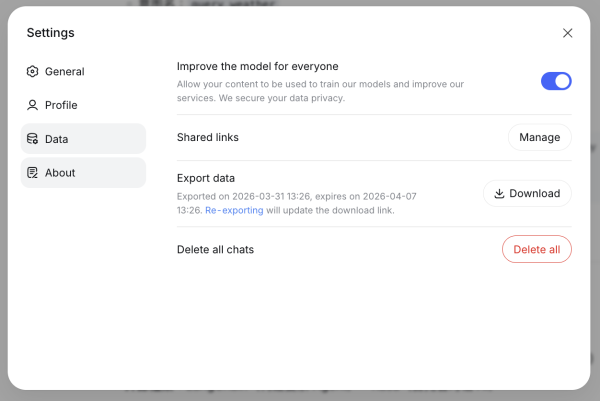
2. 格式處理:DeepSeek 的 JSON 文件架構與 OpenAI 略有不同。若 Gemini 的自動導入器出現格式錯誤,用戶可使用「YourAIScroll」插件,將 DeepSeek 對話轉換為更具兼容性的 Markdown 格式 。
技術記憶的深度繼承
DeepSeek 用戶常面臨的一個問題是「代碼風格的延續性」。通過將 DeepSeek 的歷史 JSON 檔上傳至 Gemini 的 Context Window,Gemini 可以分析用戶之前的代碼命名習慣、偏好的框架(Frameworks)以及常用的 Bug 修復邏輯 。Gemini 1.5 Pro 能夠同時處理 100,000 行代碼,這使得其在遷移 DeepSeek 技術資產後,能立即接手複雜的軟體架構規劃工作 。
第五章:Grok 支援單個回覆導出 進階導出「推理鏈」需額外腳本
捕捉實時脈絡與推理路徑
xAI 旗下的 Grok 因其能訪問 X(原 Twitter)的實時數據而具有獨特的資訊密度 。遷移 Grok 數據的核心挑戰在於捕捉其推理模式(Think Mode)。
1. 導出工具選擇:官方目前主要支援單個回覆的 PDF 導出 。為了批次移轉,技術社群開發了「Enhanced Grok Export」腳本,支援將完整的「推理鏈」導出為 JSON 或 Markdown 。
2. 遷移至 Gemini:將包含「Think Mode」標記的 Markdown 文件導入 Gemini。這能讓 Gemini 學習 Grok 在處理實時爭議性話題或突發新聞時的分析邏輯 。
對於商業分析師而言,Grok 的遷移價值在於其對社交媒體趨勢的預判數據。將這些歷史分析導入 Gemini 後,可以利用 Gemini 更強大的多模態能力(處理趨勢圖表與音訊)進行更長週期的市場預測 。
第六章:豆包(Doubao)與字節系 AI 的記憶整合
管理記憶片段
豆包的記憶機制採用動態更新模式,而非永久靜態存儲。這使得數據提取需要更主動的介入 。

1. 記憶管理介面:用戶需進入「設置」->「記憶」頁面。這裡會列出豆包自動記住的單條資訊(如職業、習慣、興趣)。
2. 提取指令:由於豆包目前缺乏成熟的批量 JSON 導出功能,用戶必須通過提示詞驅動提取。
提示詞示範:「請展示你目前對我的所有記憶紀錄。請將其分類為個人背景、偏好設定及過往專案,並確保以 Markdown 格式輸出代碼塊。」 。
3. 導入與更新:獲取豆包的記憶列表後,將其加入 Gemini 的「Saved memories」。
第七章:Gemini 導入操作流程與系統限制
分步指南:從 ZIP 到 AI 知識庫
當用戶準備好上述工具的導出檔案後,即可進入 Gemini 的導入程序:
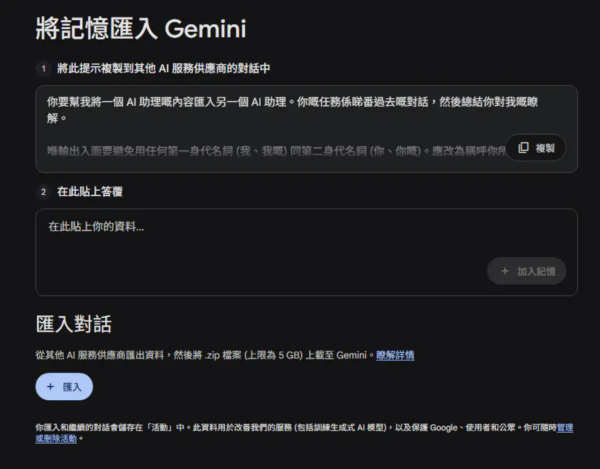
訪問入口:在
gemini.google.com介面,點擊左下角的「Settings & help」圖標 。選擇功能:點擊「Import memory to Gemini」。此頁面會顯示兩個選項:「Import memory」與「Import chats」 。
上傳檔案:在「Import chats」下點擊「Add」,上傳 5 GB 以內的 ZIP 檔案 。
貼入提示詞結果:在「Import memory」對話框中,貼入從其他 AI 提取的 Persona 總結 。
確認與索引:點擊「Add memory」。Gemini 將會創建一個專門的對話線索(Thread)來解析這些數據,並將提取的精華資訊寫入帳號的永久記憶層 。
導入規格與限制一覽表
| 項目 | 限制/規格 | 備註 |
| 檔案大小 | 每個 ZIP 最高 5 GB |
超過此限建議分批導出或使用 Prompt 提取。 |
| 每日頻率 | 每天最多上傳 5 個檔案 |
系統需要時間進行後台索引與向量化。 |
| 檔案類型 |
|
內部檔案可包含 .json, .html, .md, .txt。 |
| 上下文視窗 | 100 萬至 200 萬 Token |
決定了模型能同時回顧多少歷史導入紀錄。 |
| 地理限制 | 初期不支援 EEA、英國、瑞士 |
受限於當地的數據隱私條例。 |
第八章:進階優化:如何提升遷移後的 AI 表現
使用 Context Caching 降低延遲
遷移海量數據後,用戶可能會發現回應速度變慢。這是因為模型在每次對話時都要重新掃描數百萬 Token。Google 在 2026 年對此提供了「顯式緩存」(Explicit Caching)解決方案 。
對於開發者或重度研究者,可以通過 Gemini API 設置一個長期有效的緩存塊。例如,將過去五年的開發對話紀錄緩存,有效期設置為 48 小時或更長。這樣,無論用戶如何頻繁切換話題,Gemini 都能在幾毫秒內調用歷史背景,而無需重新讀取整個 ZIP 包 。
構建個人知識庫「Gems」
導入的記憶與對話可以進一步轉化為「Gems」——Gemini 的自定義 AI 機器人 。
創建 Gem:在側邊欄選擇「Explore Gems」並新建一個 。
掛載數據:將遷移來的 Markdown 檔案或技術文檔作為 Gem 的「Knowledge Base」上傳 。
設定角色:在指令中明確指出:「你是一位繼承了我過去三年 ChatGPT 歷史記憶的助手,請根據這些數據提供的背景,協助我進行決策。」 。

結論:打破 AI 平台壁壘 提高工作效率
Google Gemini 這次推出的記憶移轉功能,徹底改變了 AI 行業的競爭遊戲規則。它宣告了「數據孤島」時代的終結,開闢了一個「數位人格隨身帶」的新局面 。用戶不再需要為了保留過去的工作成果而勉強忍受某個平台的技術短板,AI 模型之間的切換將變得像更換手機瀏覽器一樣簡單。
對話紀錄/記憶遷移核心建議:

優先處理身份記憶:先用 Prompt 提取身份與規則,這是影響 AI 語氣與智商的最直接因素 。
有選擇地導入對話:並非所有對話都有保留價值。過濾掉無意義的閒聊,僅導入專案相關、研究相關的數據包,能提升 Gemini 的解析精準度 。
建立緩存機制:針對大型數據導入,利用 Context Caching 技術優化性能與成本 。
Source: ezone.hk
【相關報道】
【相關話題】Gemini解夢指令︰發夢俾蛇咬、甩牙代表咩? 拆解夢境迷思【附15個解夢Prompts】
半夜嚇醒 Google「發夢俾蛇咬代表咩」或者「發夢甩牙吉凶」?原來西方心理學同東方《周公解夢》結論大不同!本文教你結合中西玄學,利用 AI 讀懂潛意識警告。內附 15 個超實用 Gemini 解夢指令 (Prompt) 懶人包。《ezone》親自實測指令拆解「俾蛇咬」夢境,揭開隱藏運勢密碼,快啲入嚟學嘢!

Source: ezone.hk